Introducing Connector Private Networking: Join The Upcoming Webinar!
Disaster Recovery for Multi-Datacenter Apache Kafka Deployments
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Datacenter downtime and data loss can result in businesses losing a vast amount of revenue or entirely halting operations. To minimize the downtime and data loss resulting from a disaster, enterprises create business continuity plans and disaster recovery strategies.
A disaster recovery plan often requires multi-datacenter Apache Kafka® deployments where datacenters are geographically dispersed. If disaster strikes—catastrophic hardware failure, software failure, power outage, denial of service attack, or any other event that causes one datacenter to completely fail—Kafka continues running in another datacenter until service is restored. Here is a Confluent multi-datacenter reference architecture:
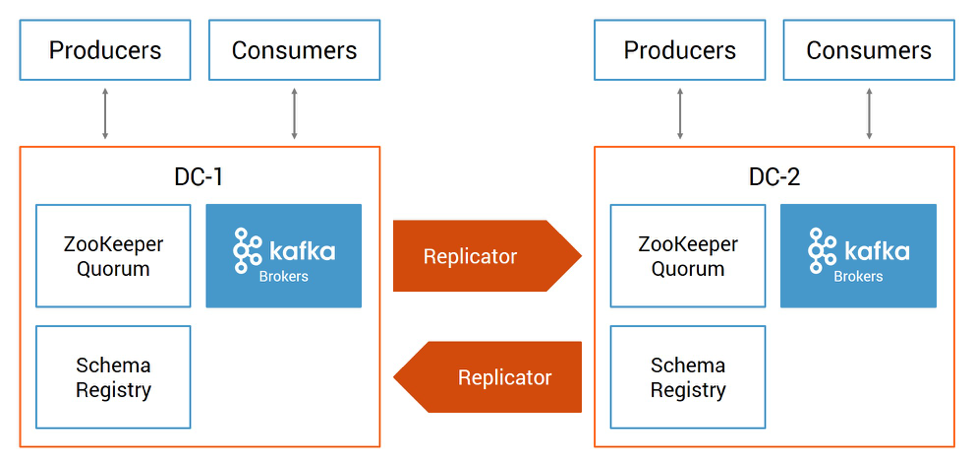
The details of your design will vary depending on your business requirements. You may be considering an active-passive design (one-way data replication between Kafka clusters), active-active design (two-way data replication between Kafka clusters), client applications that read from just their local cluster or both local and remote clusters, service discovery mechanisms to enable automated failovers, geo locality offerings, etc.
Confluent Replicator is the key to any of these multi-datacenter designs. It manages multiple Kafka deployments and provides a centralized configuration of cross-datacenter replication. It reads data from the origin cluster and writes that data to the destination cluster. As topic metadata or partition count changes in the origin cluster, it replicates the changes in the destination cluster. New topics are automatically detected and replicated to the destination cluster.
In our white paper “Disaster Recovery for Multi-Datacenter Apache Kafka Deployments“, we discuss multi-datacenter designs and building blocks:
- Data replication
- Timestamp preservation
- Preventing cyclic repetition of topics
- Resetting consumer offsets
- Centralized schema management
This white paper is a practical guide for configuring multiple Kafka clusters so that if a disaster scenario strikes, you have a working plan for failover, failback, and ultimately successful recovery. Please download the white paper to follow these recommendations to strengthen your disaster recovery plan.
Additional Resources
- Download Confluent Platform
- Confluent Professional Services: If you would like assistance designing your multi-datacenter solution or the disaster recovery plan
- Confluent Replicator documentation and related Docker tutorial
- Confluent Schema Registry
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Schema Registry Clients in Action
Learn about the bits and bytes of what happens behind the scenes in the Apache Kafka producer and consumer clients when communicating with the Schema Registry and serializing and deserializing messages.

How to Securely Connect Confluent Cloud with Services on Amazon Web Services (AWS), Azure, and Google Cloud Platform (GCP)
The rise of fully managed cloud services fundamentally changed the technology landscape and introduced benefits like increased flexibility, accelerated deployment, and reduced downtime. Confluent offers a portfolio of fully managed...