Fast, Frictionless, and Secure: Explore our 120+ Connectors Portfolio | Join Webinar!
Putting Apache Kafka To Use: A Practical Guide to Building an Event Streaming Platform (Part 1)
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Data systems have mostly focused on the passive storage of data. Phrases like “data warehouse” or “data lake” or even the ubiquitous “data store” all evoke places data goes to sit. But in the last few years a new style of system and architecture has emerged which is built not just around passive storage but around the flow of real-time data streams.
This has become a central architectural element of Silicon Valley’s technology companies. Many of the largest of these have built themselves around real-time streams as a kind of central nervous system that connects applications and data systems, and makes available in real-time a stream of everything happening in the business. You can easily find examples of how these architectures are used at companies like Uber, Ebay, Netflix, Yelp, or virtually any other modern technology company.
At the same time a whole new ecosystem has emerged around processing real-time data streams, often related to technologies like Kafka, Storm, Samza, Flink, or Spark’s Streaming module. Though there is a lot of excitement, not everyone knows how to fit these technologies into their technology stack or how to put it to use in practical applications.
This guide is going to discuss our experience with real-time data streams and what is required to be successful with this new area of technology. All of this is based on real experience: we spent the last five years building Apache Kafka, transitioning LinkedIn to a fully stream-based architecture, and helping a number of Silicon Valley tech companies do the same thing.
The first part of the guide will give a high-level overview of what we came to call an “event streaming platform”: a central hub for real-time streams of data. It will cover the what and why of this idea.
The second part will dive into a lot of specifics and give advice on how to put this into practice effectively.
But first, what is an event streaming platform?
The Event Streaming Platform: A Clean, Well-lighted Place For Events
We built Apache Kafka at LinkedIn with a specific purpose in mind: to serve as a central hub of data streams. But why do this? There were a few motivations.
The first problem had to do with building real-time applications. We had a REST layer for building request/response services, but we found that there was a large class of applications for which this was a poor fit. In particular applications that triggered asynchronously off of activity elsewhere in the system such as our Newsfeed, our ad system, and other data-driven features. These types of services were different from the web and mobile apps we built because they did their core work decoupled from the UI actions that triggered them, but this was not possible to implement with transient REST calls. We tried instead to adopt off-the-shelf messaging systems such as ActiveMQ, but found these very difficult to manage and scale.
The second problem was around dataflow: the piping of data between systems. We had lots of data systems: relational OLTP databases, Apache Hadoop, Teradata, a search system, monitoring systems, OLAP stores, and derived key-value stores. Each of these needed reliable feeds of data in a geographically distributed environment. I’ll call this problem “data integration,” though we could also call it ETL.
I’ll talk a little about how these ideas developed at LinkedIn. At first we didn’t realize that these problems were connected at all. Our approach was very ad hoc: we built jerry-rigged piping between systems and applications on an as needed basis and shoe-horned any asynchronous processing into request-response web services. Over time this set-up got more and more complex as we ended up building pipelines between all kinds of different systems:
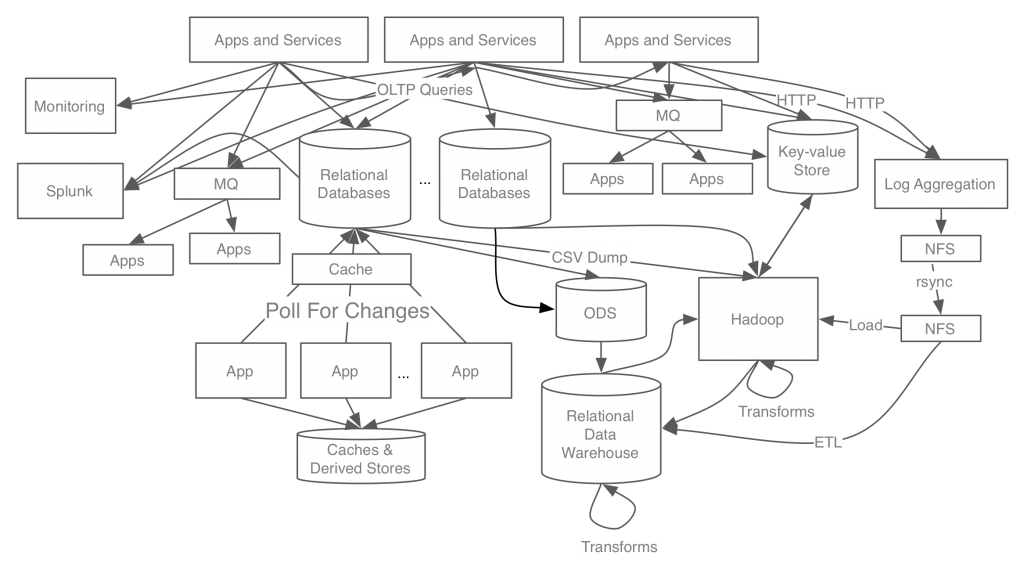
Each of the pipelines was problematic in its own ways. Our pipeline for log data was scalable but lossy and could only deliver data with high latency. Our pipeline between Oracle instances was fast, exact, and real-time, but not scalable and not available to non-Oracle systems. Our pipeline of Oracle data for Hadoop was periodic CSV dumps—high throughput, but batch. Our pipeline of data to our search system was low latency, but unscalable and tied directly to the database. Our messaging systems were low latency but unreliable and unscalable.
As we added data centers geographically distributed around the world we had to build out geographical replication for each of these data flows. As each of these systems scaled, the supporting pipelines had to scale with them. Building simple duct tape pipelines had been easy enough but scaling these and operationalizing them was an enormous effort. I felt that my team, which was supposed to be made up of distributed systems engineers, was really acting more as distributed system plumbers.
Worse, the complexity meant that the data was always unreliable. Our reports were untrustworthy, derived indexes and stores were questionable, and everyone spent a lot of time battling data quality issues of all kinds. I remember an incident where we checked two systems that had similar data and found a discrepancy; we checked a third to try to determine which of these was correct and found that it matched neither.
At the same time we weren’t just shipping data from place to place; we also wanted to do things with it. Hadoop had given us a platform for batch processing, data archival, and ad hoc processing, and this had been successful, but we lacked an analogous platform for low-latency processing. Most user- and customer-facing applications were difficult to build in a batch fashion as this required piping large amounts of data into and out of Hadoop. We needed something asynchronous from the user but fast. But these types of applications had no natural home in our infrastructure stack and we mostly ended up trying to cram these requirements into databases and request response services that were a particularly unnatural fit.
After struggling with the resulting sprawl for years we decided in 2010 to focus on building a system that would focus on modeling streams of data. This would allow us to both transport these streams of data to all the systems and applications that needed them as well as build rich real-time applications on top of them. This was the origin of Apache Kafka.
We imagined something like this:
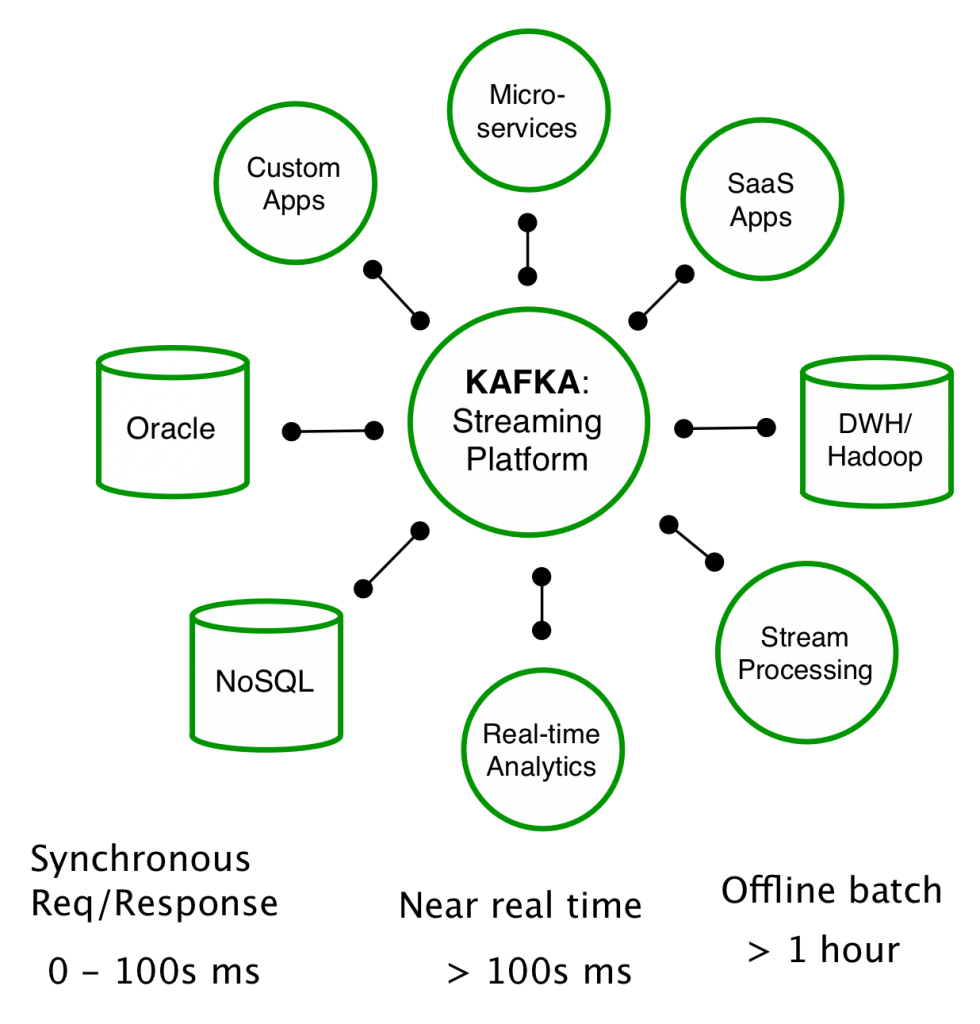
For a long time we didn’t really have a name for what we were doing (we just called it “Kafka stuff” or “the global commit log thingy”) but over time we came to call this kind of data “stream data”, and the concept of managing this centrally an “event streaming platform.”
Our resulting system architecture went from the ugly spaghetti of pipelines I described before to a much cleaner stream-centric system:
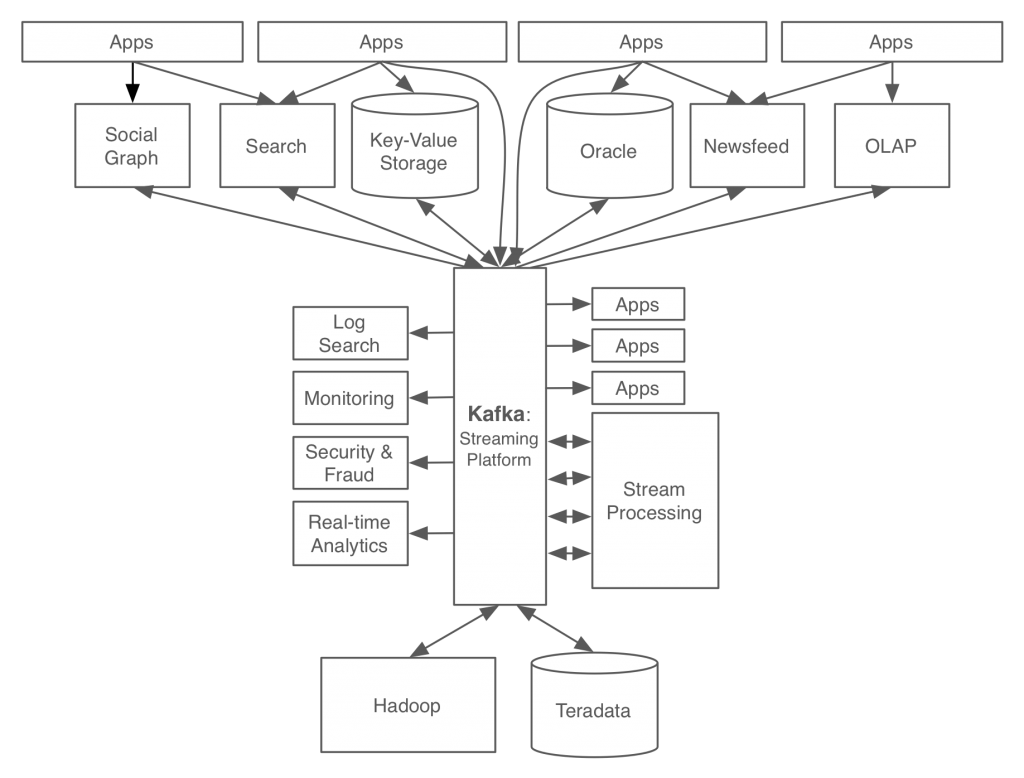
In this setup Kafka acts as a kind of universal pipeline for data. Each system can feed into this central pipeline or be fed by it; applications or stream processors can tap into it to create new, derived streams, which in turn can be fed back into the various systems for serving. Continuous feeds of well-formed data act as a kind of lingua franca across systems, applications, and data centers.
For example if a user updates their profile that update might flow into our stream processing layer where it would be processed to standardize their company information, geography, and other attributes. From there that stream might flow into search indexes and our social graph for querying, into a recommendation system for job matching; all of this would happen in milliseconds. This same flow would load into Hadoop to provide that data to the warehouse environment.
This usage at LinkedIn grew to phenomenal scale. Today at LinkedIn Kafka handles over 1 trillion events per day spread over a number of data centers. It became the backbone for data flow between systems of all kinds, the core pipeline for Hadoop data, and the hub for stream processing and real-time applications.
Since Kafka was open source this usage spread beyond LinkedIn into companies of all kinds doing similar things.
In the rest of this article I’m going to outline a few details about this stream-centric world view, how it works, and what problems it solves.
Streaming Data
Most of what a business does can be thought of as streams of events. Sometimes this is obvious. Retail has streams of orders, sales, shipments, price adjustments, returns, and so on. Finance has orders, stock prices, and other financial time series. Web sites have streams of clicks, impressions, searches, and so on. Big software systems have streams of requests, security, errors, machine metrics, and logs. Indeed one view of a business is as a kind of data processing system that takes various input streams and produces corresponding output streams (and maybe some physical goods along the way).
This view of data can seem a little foreign to people who are more accustomed to thinking of data as rows in databases rather than as events, so let’s look at a few practical aspects of event data.
The Rise of Events and Event Streams
Your database stores the current state of your data. But the current state is always caused by some actions that took place in the past. The actions are the events. Your inventory table is the state that results from the purchase and sale events that have been made, bank balances are the result of credits and debits, and the latency graph for your web server is an aggregation of the stream of HTTP request times.
Much of what people refer to when they talk about “big data” is really the act of capturing these events that previously weren’t recorded anywhere and putting them to use for analysis, optimization, and decision making. In some sense these events are the other half of the story the database tables don’t tell: they are the story of what the business did.
Event data performance has always been present in finance, where stock ticks, market indicators, trades, and other time series data are naturally thought of as event streams.
But the tech industry popularized the most modern incarnation of technology for capture and use of this data. Google transformed the stream of ad clicks and ad impressions into a multi-billion dollar business. In the web space event data is often called “log data”, because, lacking any proper infrastructure for their events, log files are often where the events are put. Systems like Hadoop are often described as being for “log processing”, but that usage might be better described as batch event storage and processing.
Web companies were probably the earliest to do this because the process of capturing event data in a web site is very easy: a few lines of code can add tracking that records what users on a website did. As a result a single page load or mobile screen on a popular website is likely recording dozens or even hundreds of these events for analysis and monitoring.
You will sometimes hear about “machine generated data”, but this is just event data by another name. In some sense virtually all data is machine generated, since it is made by computer systems.
Likewise there is a lot of talk about device data and the “internet of things”. This is a phrase that means a lot of things to different people, but a large part of the promise has to do with applying the same data collection and analytics of big web systems to industrial devices and consumer goods. In other words, more event streams.
Databases Are Event Streams
Event streams are an obvious fit for log data or things like “orders”, “sales”, “clicks” or “trades” that are obviously event-like. But, like most people, you probably keep much of your data in databases, whether relational databases like Oracle, MySQL, and Postgres, or newer distributed databases like MongoDB, Cassandra, and Couchbase. These would seem at first to be far removed from the world of events or streams.
But, in fact, data in databases can also be thought of as an event stream. The easiest way to understand the event stream representation of a database is to think about the process of creating a backup or standby copy of a database. A naive approach to doing this might be to dump out the contents of your database periodically, and load this up into the standby database. If we do this only infrequently, and our data isn’t too large, than taking a full dump of all the data may be quite feasible. In fact many backup and ETL procedures do exactly this. However this approach won’t scale as we increase the frequency of the data capture: if we do a full dump of data twice a day, it will take twice the system resources, and if we do it hourly, 24 times as much. The obvious approach to make this more efficient is to take a “diff” of what has changed and just fetch rows that have been newly created, updated, or deleted since our last diff was taken. Using this method, if we take our diffs twice as often, the diffs themselves will get (roughly) half as big, and the system resources will remain more or less the same as we increase the frequency of our data capture.
Why not take this process to the limit and take our diffs more and more frequently? If we do this what we will be left with is a continuous sequence of single row changes. This kind of event stream is called change capture, and is a common part of many databases systems (Oracle has XStreams and GoldenGate, MySQL has binlog replication, and Postgres has Logical Log Streaming Replication).
By publishing the database changes into the event streaming platform you add this to the other set of event streams. You can use these streams to synchronize other systems like a Hadoop cluster, a replica database, or a search index, or you can feed these changes into applications or stream processors to directly compute new things off the changes. These changes are in turn published back as streams that are available to all the integrated systems.
What Is an Event Streaming Platform for?
An event streaming platform has two primary uses:
- Stream processing: It enables continuous, real-time applications built to react to, process, or transform streams. This is the natural evolution of the world of Enterprise Messaging which focused on single message delivery, stream processing gives you that and more.
- Data Integration: The event streaming platform captures streams of events or data changes and feeds these to other data systems such as relational databases, key-value stores, Hadoop, or the data warehouse. This is a streaming version of existing data movement technologies such as ETL systems.
The event streaming platform acts as a central hub for data streams. Applications that integrate don’t need to be concerned with the details of the original data source, all streams look the same. It also acts as a buffer between these systems—the publisher of data doesn’t need to be concerned with the various systems that will eventually consume and load the data. This means consumers of data can come and go and are fully decoupled from the source.
If you adopt a new system you can do this by tapping into your existing data streams rather than instrumenting each individual source system and application for each possible destination. The streams all look the same whether they originated from an application, a log file, a database, Hadoop, a stream processing system, or wherever else. This makes adding a new data system a much cheaper proposition—it need only integrate with the event streaming platform not with every possible data source and sink directly.
A similar story is important for Hadoop which wants to be able to maintain a full copy of all the data in your organization and act as a “data lake” or “enterprise data hub”. Directly integrating each data source with HDFS is a hugely time consuming proposition, and the end result only makes that data available to Hadoop. This type of data capture isn’t suitable for real-time processing or syncing other real-time applications. Likewise this same design pipeline can run in reverse: Hadoop and the data warehouse environment can publish out results that need to flow into appropriate systems for serving in customer-facing applications.
The stream processing use case plays off the data integration use case. All the streams that are captured for loading into Hadoop for archival are equally available for continuous “stream processing” as data is captured in the stream. The results of the stream processing are just a new, derived stream. This stream looks just like any other stream and is available for loading in all the data systems that have integrated with the event streaming platform.
Once a stream of data is in Kafka there are a number of options for building real-time applications around it. This stream processing can be done using simple application code that reads and writes streams of data using Kafka as a messaging layer. However Kafka performance also provides a very powerful stream processing api that allows easily building state of the art stream processing applications with no additional moving parts needed beyond the Kafka cluster. Kafka can also integrate with external stream processing layers such as Storm, Samza, Flink, or Spark Streaming.
Stream processing acts as both a way to develop real-time applications but it is also directly part of the data integration usage as well: integrating systems often requires some munging of data streams in between.
What Does an Event Streaming Platform Need to Do?
I’ve discussed a number of different Kafka use cases. Each of these Kafka use cases has a corresponding event stream, but each stream has slightly different requirements—some need to be fast, some high-throughput, some need to scale out, etc. If we want to make a single platform that can handle all of these uses what will it need to do?
I think the following are the key capabilities of an event streaming platform:
- Pub/Sub: An event streaming platform must enable real-time publishing and subscribing to data streams at scale, in particular:
- It must provide single-digit latency so it is usable by real-time applications
- It must be able to handle high volume data streams such as are common for log data, IoT, or other usage across many applications in a company
- It must enable integration with passive data systems such as databases as well as applications that actively publish events
- Process: It must enable the real-time stream processing of streams at scale
- Must support modern stream processing capabilities to power real-time applications or streaming transformations
- Store: It must be able to reliably store streams of data at scale. In particular:
- It must give strong replication and ordering guarantees to be able to handle critical updates such as replicating the changelog of a database to a replica store like a search index, delivering this data in order and without loss.
- It must be able to buffer or persist data for long periods of time. This enables integration with batch systems (such as a data warehouse) that only load data periodically, as well as allowing stream processing systems to reprocess feeds when their logic changes.
- This storage must scale cheaply enough to make the platform viable at scale
An event streaming platform needs to do all of these while remaining continuously available and being used at company-wide scale. This type of platform usually begins with a single application, but the ability to serve a single application isn’t sufficient since the power of the event streaming platform grows as more applications share it. It needs to be able to grow to support the full set of applications and data flows that power a modern digital company.
What is Apache Kafka?
Apache Kafka is a distributed system designed for streams. It is built to be fault-tolerant, high-throughput, horizontally scalable, and allows geographically distributing data streams and stream processing applications.
Kafka is often categorized as a messaging system, and it serves a similar role, but provides a fundamentally different abstraction. The key abstraction in Kafka is a structured commit log of updates:
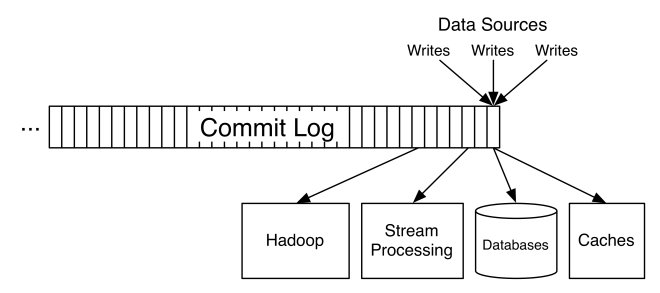
A producer of data sends a stream of records which are appended to this log, and any number of consumers can continually stream these updates off the tail of the log with millisecond latency. Each of these data consumers has its own position in the log and advances independently. This allows a reliable, ordered stream of updates to be distributed to each consumer.
The log can be sharded and spread over a cluster of machines, and each shard is replicated for fault-tolerance. This gives a model for parallel, ordered consumption which is key to Kafka’s use as a change capture system for database updates (which must be delivered in order).
Kafka is built as a modern distributed system. Data is replicated and partitioned over a cluster of machines that can grow and shrink transparently to the applications using the cluster. Consumers of data can be scaled out over a pool of machines as well and automatically adapt to failures in the consuming processes.
A key aspect of the Kafka architecture is that it handles persistence well. A Kafka broker can store many TBs of data. This allows usage patterns that would be impossible in a traditional database:
- A Hadoop cluster or other offline system that is fed off Kafka can go down for maintenance and come back hours or days later confident that all changes have been safely persisted in the up-stream Kafka cluster.
- When synchronizing from database tables it is possible to initialize a “full dump” of the database so that downstream consumers of data have access to the full data set.
These features make Kafka applicable well beyond the uses of traditional enterprise messaging systems.
Event-driven Applications
Since we built Kafka as an open source project we have had the opportunity to work closely with companies who put it to use and to see the general pattern of Kafka adoption: how it first is adopted and how its role evolves over time in their architecture.
The initial adoption is usually for a single particularly large-scale app that requires scalability beyond what a traditional messaging system can handle.
From there, though, the usage spreads. All streams in Kafka are innately multi-subscriber: a topic in Kafka can be consumed by one app or many. This means that streams in Kafka naturally draw in additional applications that need that data. Existing applications will end up tapping into the event streams to react to what is happening more intelligently, and new applications will be built to harness intelligence derived off these streams. These applications tend to draw in their own new data streams, which in turn draw in more applications. As long as these data streams are well-structured this can be a powerful virtuous cycle that builds a rich streaming ecosystem.
For example, at LinkedIn we originally began capturing a stream of views to jobs displayed on the website as one of many feeds to deliver to Hadoop and our relational data warehouse. However this ETL-centric use case soon became one of many and the stream of job views over time began to be used by a variety of systems:
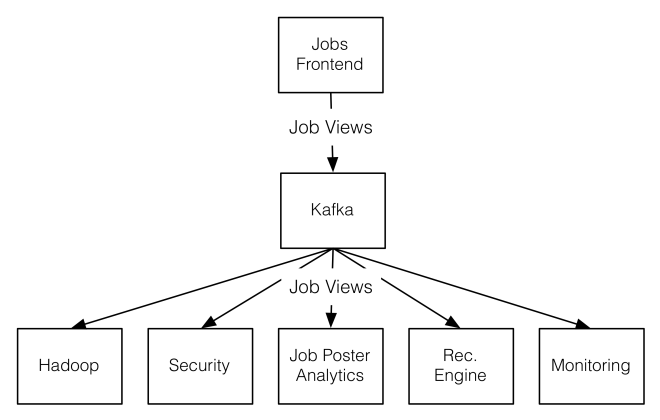
Note that the application that showed jobs didn’t need any particular modification to integrate with these other uses. It just produced the stream of jobs that were viewed. The other applications tapped into this stream to add their own processing. Likewise when job views began happening in other applications—mobile applications—these are just added to the global feed of events, the downstream processors don’t need to integrate with new upstream sources.
How Does an Event Streaming Platform Relate to Existing Things?
Let’s talk briefly about the relationship this event streaming platform concept has with other things in the world.
Messaging
An event streaming platform is similar to an enterprise messaging system—it receives messages and distributes them to interested subscribers. You consider it as a kind of messaging 2.0 if you like, but there are three important differences:
- Messaging systems are typically run in one-off deployments for different applications. Because an event streaming platform runs as a cluster and can scale, a central instance can support an entire datacenter.
- Messaging systems do a poor job of storing data and this limits them to streams which have only real-time consumption. However many integrations require more than this.
- Messaging systems do not provide semantics that are easily compatible with rich stream processing, therefor they can’t really be used as the basis for the processing part of an event streaming platform.
In other words, an event streaming platform is a messaging system whose role has been re-thought at a company-wide scale.
Data Integration Tools
An event streaming platform does a lot to make integration between systems easier. However its role is different from a tool like Informatica. An event streaming platform is a true platform that any other system can choose to tap into and many applications can build around.
One practical area of overlap is that by making data available in a uniform format in a single place with a common stream abstraction, many of the routine data clean-up tasks can be avoided entirely. I’ll dive into this more in the second part of this article.
Enterprise Service Buses
I think an event streaming platform embodies many of the ideas of an enterprise service bus, but with better implementation. The challenges of Enterprise Service Bus adoption has been the coupling of transformations of data with the bus itself. Some of the challenges of Enterprise Service Bus adoption are that much of the logic required for transformation are baked into the message bus itself without a good model for multi-tenant cloud like deployment and operation of this logic.
The advantage of an event streaming platform is that transformation is fundamentally decoupled from the stream itself. This code can live in applications or stream processing tasks, allowing teams to iterate at their own pace without a central bottleneck for application development.
Change Capture Systems
Databases have long had similar log mechanisms such as Golden Gate. However these mechanisms are limited to database changes only and are not a general purpose event capture platform. They tend to focus primarily on the replication between databases, often between instances of the same database system (e.g. Oracle-to-Oracle).
Data Warehouses and Apache Hadoop
An event streaming platform doesn’t replace your data warehouse; in fact, quite the opposite: it feeds it data. It acts as a conduit for data to quickly flow into the warehouse environment for long-term retention, ad hoc analysis, and batch processing. That same pipeline can run in reverse to publish out derived results from nightly or hourly batch processing.
Stream Processing Systems
External stream processing frameworks such as Storm, Samza, Flink, or Spark Streaming can be used to provide the processing capability of an event streaming platform. They attempt to add additional processing semantics for building real-time transformations. When used in this way they would be combined with a system like Apache Kafka that provides the storage and pub/sub part of the event streaming platform. Kafka also provides advanced stream processing capabilities via built in APIs.
Whether the streaming system provides built-in stream processing capabilities like Kafka does, or whether you need to integrate a second system, the event streaming platform is best thought of as the combination of stream store, pub/sub, and processing capabilities.
What Does This Look Like In Practice?
One of the interesting things about this concept is that it isn’t just an idea, we have actually had the opportunity to “do the experiment”. We spent the last five years building Kafka and helping companies put an event streaming platform to use. At a number of Silicon Valley companies today you can see this concept in action—everything that happens in the business from user activity, to transaction processing, to database changes to operational monitoring are captured in real-time streams that are universally available to subscribed to and processed in real-time.
What is interesting about this is that what begins as simple plumbing quickly evolves into something much more. These data streams begin to act as a kind of central nervous system that applications organize themselves around.
The second half of this guide will cover some of the practical aspects of building out and managing an event streaming platform.
Next Steps
We think this technology is changing how data is put to use in companies. We are building Confluent Platform, a distribution of Kafka aimed at helping companies adopt and use it as an event streaming platform. We think Confluent Platform represents the best place to get started if you are thinking about putting an event streaming platform to use in your organization whether for a single app or at company-wide scale.
There are a few other resources that may be useful:
- I have previously written a blog post and short book about some of the ideas in this article focused on the relationship between Kafka’s log abstraction, data streams, and data infrastructure
- You can also download the Confluent Platform to try ksqlDB, the event streaming database purpose-built for stream processing applications
- Read the second part of this blog series: Putting Apache Kafka To Use: A Practical Guide to Building an Event Streaming Platform (Part 2)
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Introducing Versioned State Store in Kafka Streams
Versioned key-value state stores, introduced to Kafka Streams in 3.5, enhance stateful processing capabilities by allowing users to store multiple record versions per key, rather than only the single latest version per key as is the case for existing key-value stores today...


Delivery Guarantees and the Ethics of Teleportation
This blog post discusses the two generals problems, how it impacts message delivery guarantees, and how those guarantees would affect a futuristic technology such as teleportation.