Introducing Connector Private Networking: Join The Upcoming Webinar!
How to Survive an Apache Kafka Outage
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
There is a class of applications that cannot afford to be unavailable—for example, external-facing entry points into your organization. Typically, anything your customers interact with directly cannot go down. As we move toward an event-driven world, more and more organizations are integrating Apache Kafka® as a core dependency of these applications. If you are ingesting data and sending it somewhere for processing, then that somewhere is usually Kafka.
A distributed system with a high level of redundancy means that it is a strong candidate for the type of data offload that this type of application requires. Given the proper distribution of brokers across racks, availability zones, and datacenters, combined with the right replication settings and client acknowledgments, you can achieve a high level of reliability in the event of problems in lower-level failure domains (e.g., disks, servers, networking, and racks). Even so, in complex systems there are unforeseen failure modes, and the scope for human error is amplified by automation, which means that partial or complete cluster outage remains a low-likelihood but high-impact possibility.
Unfortunately, these types of outages do occur in the wild. The impact on applications designed based on the assumption that distributed systems cannot go down (or that if they do, then the outage will be short-lived) can be significant.
For the vast majority of applications, the outage of a system such as Kafka, which forms the foundation of intersystem communications, will be significant but can also be easily remedied. You can quickly recover a system into a working state with the right combination of operational understanding, monitoring, and processes. However, failures that are not detected and swiftly remediated can have a significant impact on applications. Data loss and application outages are possible side effects of a Kafka outage. You need to consider how your application will behave during this type of service interruption.
This blog post addresses some of the impact caused by these types of failures on applications that interact with Kafka and provides some options to handle extended outages.
This really shouldn’t happen, but stuff happens…
Availability needs to be treated like security—a practice that is applied in depth. Before you start worrying about Kafka clusters going offline and how your applications will react, you need to have the basics covered. This means:
- Know your availability objectives and plan out how you are going to address them. List the failures that the system should tolerate. There are multiple tools available from Confluent to address these issues (e.g., Multi-Region Clusters with Automatic Observer Promotion and Cluster Linking). High availability and disaster recovery are closely related—plan them properly and methodically.
- If you are running your own hardware infrastructure, make sure that you build in redundancy for networking equipment, storage, racks, and power supplies.
- Distribute your brokers so that they can survive the failure of any one piece of infrastructure.
- Configure your topics with the appropriate replication settings, taking into account producer acknowledgement.
- Monitor your hardware and software infrastructure, and ensure that you have alerting set up. This way, you can detect and remedy problems quickly.
- Upgrade your clusters and client libraries at a regular cadence. Confluent fixes bugs with every release, and in practice it is not practical for you to determine whether something that affects you is included in a release (assume this is the case by default). The older your software infrastructure is, the higher the likelihood that potential issues are minimized because an issue you haven’t yet encountered has already been fixed.
- Ensure that your deployments are automated and configuration is kept under version control. Nobody should be able to update broker configurations directly.
If you apply each of the practices above, this will significantly reduce the risk of cluster outages. If you are using Confluent Cloud, then we take care of the operational best practices around running the platform for you so you don’t have to worry about detecting issues and fixing them.
Once all of the above practices have been addressed, you should start to consider how your application will behave if something really unexpected goes wrong.
Application types that need to consider extended outages
You should pay particular attention to the potential for extended outages if one or more of the following apply:
- Your application is the entry point of data from the outside world.
- The application is a receiver rather than a poller of data.
- You have an external contract, possibly a legal obligation, around providing a high level of availability.
- The application confirms the transaction with the outside world before sending a message to Kafka. In this case, outage handling becomes a critical design consideration.
Application types and service levels
The applications that are primarily affected are those that respond to client requests. These include applications that provide web services, RPC interfaces, and some TCP-native application protocols. These applications are characterized by servicing an inflow of requests without the ability to control the flow rate. If you have a Kafka outage, then there is nowhere for these messages to go.
An application is in control of its rate of ingress if it polls a source of data. Applications of this type have a relatively simple response to managing downstream outages—they can stop consuming from the input source. Examples include applications that consume from message brokers, file systems, and databases.
When you take a close look at the polling examples above, you may notice that it is characteristic of the sort of work performed by a Kafka Connect source connector. The Connect framework ensures that these connectors shut down during a broker outage. It subsequently resumes work when connectivity is reestablished by redistributing connector tasks across the cluster’s worker nodes. Custom applications that take their input from the outside world and directly produce to Kafka need to take a more considered approach.
If you have an obligation that says the system will continue to be available, there is a high outage cost. Aside from the risk of significant business loss and reputational damage, in some cases, regulators may impose fines if your organization is subject to those types of obligations.
When you send messages matters a lot
The order of business logic relative to sends determines the importance of outage handling and constraints of your design choices. If your application completes a business operation before it sends messages to Kafka upon its completion, then extra effort needs to be applied to prevent outages and build out support mechanisms as fail-safes. If Kafka is unavailable to send messages to, there is inconsistency between what the outside world and your organization believe to be true; therefore, you need to put some backup mechanism in place.
Financial exchange trading platforms serve as an example of the type of application that works within this model and is susceptible to broker outages. In this scenario, a buy order is matched to a sell order, and the application sends a confirmation to the third-party transacting system via a high-speed channel. After this occurs, a message is then sent to Kafka for downstream processing (trade clearing, market updates, etc.).
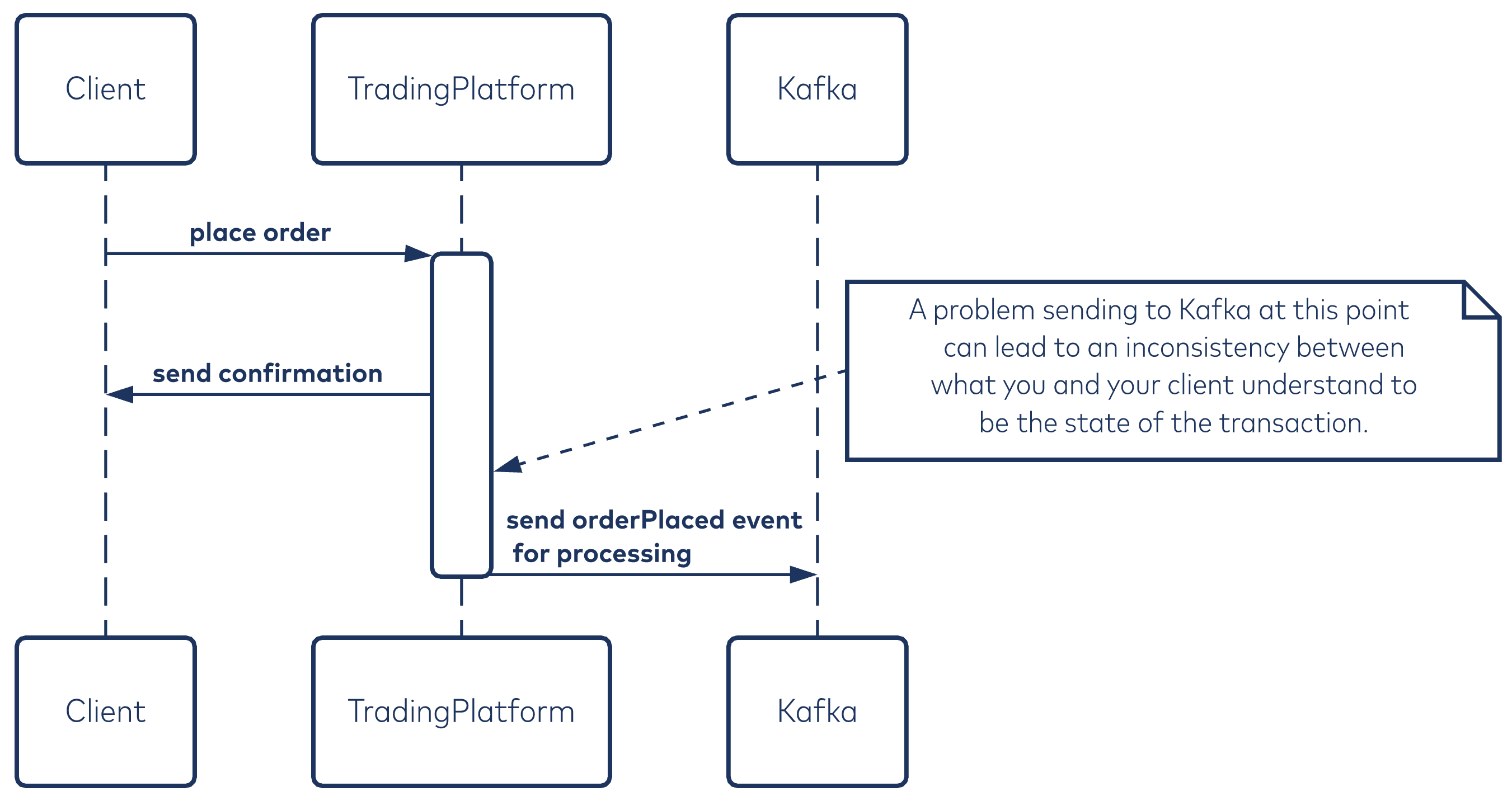
In the case of an outage, you have to ensure that these messages can be processed eventually. Keeping unsent messages around and retrying indefinitely in the hopes that the outage will rectify may eventually result in your application running out of memory. This is a crucial consideration in high-throughput applications.
If business functions are performed by systems downstream of Kafka, and the sending application only acts as an ingestion point, the situation is slightly more relaxed. If Kafka is unavailable to send messages to, then no external activity has taken place. For these systems, a Kafka outage might mean that you do not accept new transactions. In such a case, it may be reasonable to return an error message and allow the external third party to retry later. Retail applications typically fall into this category.
You need to consider what to do when applications can’t send regardless of the transaction model. The approach may be radically different depending on the value of the data and throughput levels and whether it is worth investing higher levels of effort to build supporting infrastructure. You can make any system more reliable, but there is a cutoff point beyond which the costs to do so rise significantly, and the effort is not worth it.
Characteristics of an extended outage
An outage is a situation where applications cannot publish into Kafka. Outages may partially or entirely prevent an inflow of data. The outage does not necessarily have to disable the whole Kafka cluster at the same time.
An outage occurs where:
- Multiple brokers in a cluster become unreachable around the same time
- min.insync.replicas is not achievable on sends where acks=all or no leaders are available for partitions to which the producing application wants to send
A partial cluster failure that takes out a few partitions is enough over time to completely block a producing application from sending because the memory buffers in its client library fill up.
Extended outages are not defined by any particular time window but display specific characteristics:
- Messages are unable to be sent into the client library by the application
- Messages exceed the maximum retries or start to time out
Which one of these symptoms shows up first depends on the following client configuration settings:
- The amount of memory that you have allocated to the Kafka library’s buffer
- The maximum number of retries
- The message expiry time
When the client library determines that the maximum number of retries for a message was exceeded or the message times out, the application receives exceptions or errors on callback listeners. It is essential that you do not ignore these warnings and do something sensible with the failed messages. The errors will likely affect messages sent to some partitions but not others. Keep in mind that partitions have different brokers acting as leaders for them.
At some time into the outage (seconds or minutes depending on production throughput), your application threads will be blocked from sending and will start returning errors from the send operation. How this looks mechanically depends on the client library:
- Sends in librdkafka will return an error code. The application needs to poll for broker responses to free up space within the client library before trying to send again.
- Sends using the Java client will result initially in application threads blocking and eventually timing out. This can exhaust accepting application thread pools and can manifest in the same way as multiple threads all locking on the same resource (e.g., a database table)—the system becomes unresponsive to the outside world and prevents the flow of new requests.
Is it possible to get around this through the use of in-memory queues to build a form of staged event-driven architecture (SEDA) in front of the sending code?
In such a scheme, one or more acceptor threads ingest requests, perform some processing, and enqueue them for a background thread to perform the send to the Kafka client library. This idea of separating processing stages in an application with queues is the basis for actor frameworks.
Unfortunately, in-memory queues are not a solution. To understand why, we need to talk about backpressure.
Backpressure
Let’s step back for a moment and define a buffer: It is an area that temporarily holds data. Some processing units (for want of a better description) write data into this area, while others read and remove it. Within an application, a buffer is a data structure and the processing units are the threads of execution. A queue on a conventional message broker is also a buffer; the processing units are applications that produce to and consume from it.
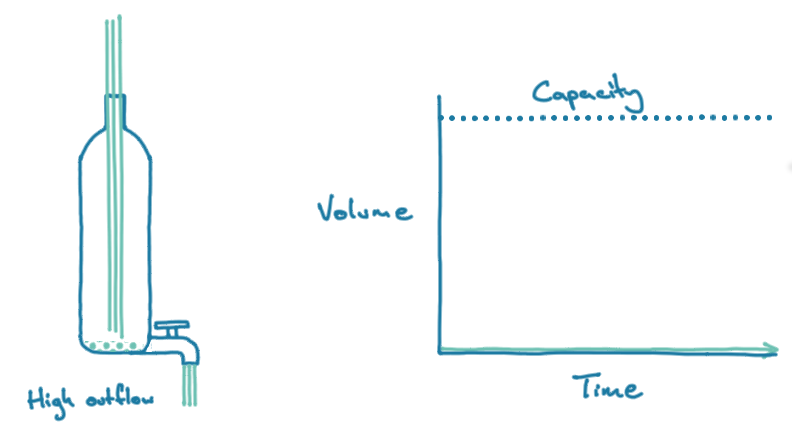
A buffer behaves much like a water bottle with a tap on the bottom of it.
A bottle has a fixed capacity. Only a finite amount of water can go into it. However, a bottle with a tap is a dynamic system—you can regulate the amount of water going in (the production rate). You can also drain water from the bottle at different speeds by opening the bottom tap to various degrees (the consumption rate).
Buffers trend toward two different states over time:
- If production rate <= consumption rate, then the buffer will trend toward empty; the bottle empties faster than it fills.
- If production rate > consumption rate, then the buffer will trend toward full; the bottle fills up despite a small amount of water leaving. Eventually, it will overflow, and you won’t be able to add more water if the outflow is blocked nor add water at the same rate if it is merely low.
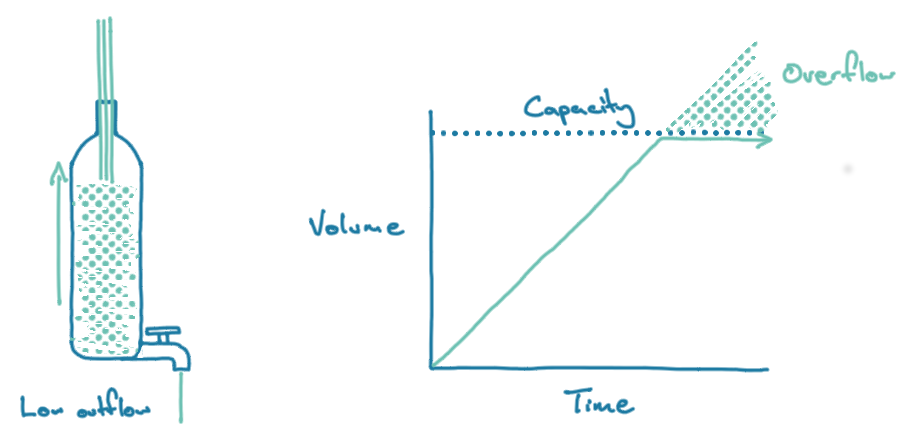
This overflow of water should give you some sense of how backpressure works. If a send process writes to a buffer that is being consumed at a slower pace, then the buffer will eventually fill up. If the send process is getting data from an upstream application, it will reach capacity and push back on the upstream system.
This is what happens during extended outages. The application sends messages into the Kafka client library, while at the same time, the background thread that performs the send to the broker is unable to release any of that data. The bottom tap is closed while the flow of water into the bottle continues.
Let’s go back to the idea of adding another buffer to the system and separating the acceptance of inbound requests from the send into the Kafka client library.
Using the bottle analogy, this is the equivalent of introducing another bottle with a tap above the initial bottle with a tap and running a hose between the two bottles.
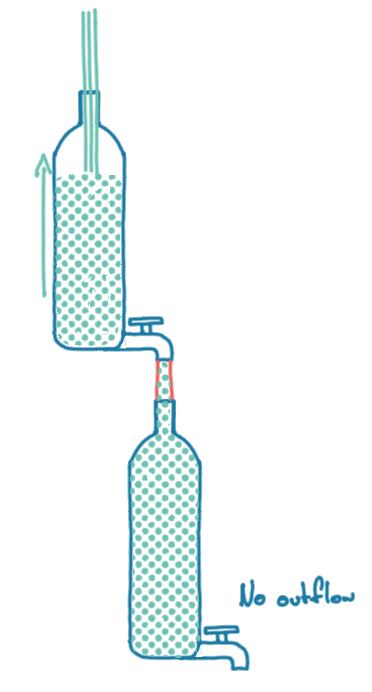
If the bottom bottle is not drained quickly enough, it will eventually fill up, and the pressure will go back up the hose and proceed to fill up the top water bottle, which will eventually overflow.
Only by ensuring that the consumption rate trends toward being faster than the production rate can you ensure consistent flow in a dynamic system in the long term. It can rise and fall with variable input, but the water level (a work in progress) should trend down over time. You can enlarge the buffers to deal with a short outage, but that is only a short-term solution.
You should always be careful when introducing buffers. Applications that hold data inside an in-memory buffer can crash while waiting for the outflow to open again. This is the equivalent of breaking the bottle before it can release its contents.
So what can you do about it?
Applications that send into a message broker need to be able to make a distinction between two types of error and react correspondingly:
- Permanent: Regardless of the number of retries, the application will never be able to send the message. An example of this is a message serialization failure, where messages are typically written to a dead letter channel, such as a known and monitored log or an exception table in a database.
- Temporary/transient: If the application resends the message, then it might succeed. An example of this is a delivery timeout.
You can deal with failed transient sends in several ways:
- Drop failed messages
- Exert backpressure further up the application and retry sends
- Send all messages to alternative local storage, from which they will be ingested into Kafka asynchronously
- Send timed-out messages to local storage and ingest them into Kafka by a side process
- Implement a circuit breaker to flush messages to alternative storage (e.g., disk or local message broker) and a recovery process to then send the messages on to Kafka
- Perform dual writes to multiple Kafka clusters
Things to consider
Ordering
Any messages that time out and are resent into the Kafka producer API, either via an external retry or a side channel, will lose their original send order. That is always true for messages retried by the application unless it performs synchronous single-message sends, which is not an option for anything other than low-volume applications because it is too slow.
Writing to local storage
Writing messages to local storage is a component of a number of the options discussed here; however, it is not as simple as writing the messages to the end of a file.
You need to address the following concerns in writing failed/timed-out messages to local storage:
- What is the resiliency of the local storage? How does it handle a failed disk?
- Is the local storage fast enough to accommodate the throughput? In a system where the sending application takes up a significant amount of memory, disk writes will go through a small page cache and involve a high number of flushes to disk.
- How do you guarantee the durability of the data in case the system shuts down? Applications that write to disk via the file system should periodically flush their writes to disk. They can do this by calling the fsync() function. The latency of the I/O pipeline limits the performance of this operation, which the application calls synchronously.
You can achieve higher throughput with lower durability by using asynchronous disk APIs, such as libaio or io_uring via liburing. The frequency at which writes should occur to the local physical disks needs to be considered alongside the amount of data that resides in various application buffers that have not yet been written and would be lost if the system had a power outage.
- Should messages be written to a single file for all message types or one per target topic or partition? You need to consider this when the partitioning is predefined and not performed by a partitioner within the client library based on the message key.
- When ingesting from a file into Kafka, how do you keep track of which messages have already been read? This should be considered if your recovery process shuts down midway through its work.
- Any ingesting system needs to be able to handle partial writes (corrupted files).
- What should be the maximum size of a data file? When does the application roll over to a new file?
- When are consumed files deleted from the system?
These considerations are at the heart of the functionality of a message broker. You should consider writing messages to a broker that is co-located with the application rather than reimplementing the logic within your application. This form of co-location may be problematic for applications whose CPU and memory usage are highly optimized.
The implementation of KIP-500 provides a new design option consisting of a single-broker cluster that you can co-locate with your application as an ingestion point, and from there, mirror the affected topics to a central cluster via Cluster Linking. These types of hub-and-spoke architectures are already common in certain geographically distributed use cases; the use of individual brokers as spokes opens up new applications due to a smaller footprint.
Strategies for handling outages gracefully
Option 1: Drop failed messages
This strategy is more generally known as load shedding. When a callback handler receives a transient error related to a sent message, it removes associated data from upstream data structures and performs no further actions. The application may log the event.
The situation should be externally visible to operators via monitoring.
Pro:
- Simple to implement
Con:
- Data loss occurs, which is a big deal if the application sends anything other than low-value informative messages
Option 2: Exert backpressure further up the application and retry
The application resends timed-out messages to the client library. At some point, dictated by unsent messages or something similar, the application closes itself off to further inbound traffic until messages start to flow again.
Applications that poll for their inputs can stop polling, resulting in the same effect.
Pros:
- No external dependencies required
- No message loss
Cons:
- Implementing retries over the top of Kafka’s client libraries is discouraged. These already contain a retry mechanism that maintains message ordering and ensures idempotent production. If messages time out, the library has done all that it can to deliver to the broker.
- Message ordering is lost. Consider a situation where the application sends messages in the order [A, B, C]. When message A times out, is resent, and subsequently accepted, the messages will appear on the topic in the order [B, C, A].
- A consumer may receive the same payload twice if a producer resends a message that timed out after being sent to a broker and did not initially receive a response.
- Blocking the system to inbound traffic effectively closes your service without warning to external parties.
- Modifying the application design to exert backpressure may require an explicit API contract change at the system boundary. It would be good to let your clients know that backpressure is a possibility so that they can adapt accordingly, if they are not already aware.
Option 3: Write all messages locally and ingest them into Kafka asynchronously
The application sends all messages to alternative local storage. A mechanism such as a Kafka Connect connector then ingests these into Kafka asynchronously.
Pros:
- This option is less complex than the circuit breaker option
- The application can continue accepting inbound traffic for a much longer time than memory alone, though the time varies depending on the size of the local storage
- No manual intervention is required to recover back into a normal working state
- No message loss
Cons:
- Local storage will be much less reliable than the cluster that it protects and is a potential single point of failure
- Message flow will see additional end-to-end latency in the standard case
Option 4: Send timed-out messages to local storage and ingest these into Kafka by a side process
This option uses local storage as a dead letter channel. A batch process imports these messages into Kafka once the system recovers to a normal state.
Pros:
- Low application complexity
- The application can continue accepting inbound traffic for a much longer time than memory alone; the amount of time depends on the size of the local storage
- No message loss
Cons:
- Message ordering is lost
- You need to consider the complexities of writing to local storage
- You have to intervene manually on a per-application-instance basis to recover all messages
Option 5: Implement a circuit breaker to temporarily push messages to local storage
The system disables data flow to Kafka on failure and reroutes failed messages to local storage. The application plays back these messages from local storage and resends when Kafka recovers. Regular flow is then resumed.
You typically use the circuit breaker pattern for synchronous interactions, such as a web service or database invocations that will fail quickly. Attempting to implement this pattern over the top of a Kafka client, which is an asynchronous library, needs to account for the following:
- Multiple messages will be inside the producer’s queues. Timing issues may arise around the opening and closing of the circuit breaker.
- When should the circuit breaker be opened (disabling new traffic flow)?
It is difficult to make sense of the cluster state based on a Kafka client (via JMX in Java or librdkafka statistics). You should instead monitor the data error rate (e.g., errored delivery reports). The application should signal an alarm if this rate exceeds some threshold or if the number of outstanding messages remains too high. This approach covers all types of cluster failures without any specific knowledge of client internals. - What closes the circuit breaker reenabling flow? An application can use an in-process probe that checks the communication channel’s status for this purpose. In the case of a message broker, that may involve a combination of a producer and a consumer sending periodic messages. This agent would communicate over a dedicated topic, whose partitions are distributed across all brokers.
- How do you recover the messages that have failed?
Pros:
- The application can continue accepting inbound traffic for a much longer time than memory alone, limited by the local storage size
- No manual intervention is required to recover back into a normal working state
- No message loss
Cons:
- Complex to implement
- Message ordering is lost
- You need to consider the complexities of writing to local storage
Option 6: Dual writes to parallel Kafka clusters
The sending application writes messages twice. Applications consuming from the affected topics must do so from two clusters and discard previously seen messages.
We have seen similar schemes applied in systems requiring ordered ledgers, where applications send messages to two locations. Consumers do not deduplicate using the typical method (idempotent consumer) of keeping track of previously seen business keys that uniquely identify each message payload and discarding duplicates—a read- and write-intensive process. Instead, they use a technique based on sequencing via a monotonically incrementing counter stamped on each message by the sending process.
The consuming system pulls messages from both clusters and keeps track of the highest counter value. It discards messages with a counter that is equal to or lower than the highest counter previously seen. You can avoid modifying message payloads by storing these counters in a message header.
Pros:
- The system will continue to work even if an entire Kafka cluster is unavailable
- No message loss
- No loss of ordering
Cons:
- Additional producer logic is required to avoid out-of-order processing on the consumer side (e.g., monotonically incrementing counters)
- Additional logic is required in the sending library to produce into two locations
- Topic configuration must be kept identical in both clusters
- This configuration does not guard against every issue—the application may not send messages to either cluster in the case of networking problems
- A backup process that would record failed messages (e.g., Option 5) is still required
- This option requires double the hardware and doubles the licensing costs
Summary
As part of any Kafka deployment and topic design, it is important to plan around common failures:
- Machine outages
- Rack/availability zone outages
- Networking failures
In a self-managed environment, you can address these through a combination of appropriate broker placement, replication settings, and redundancy.
Monitoring of your Kafka clusters is essential for detecting failures before they escalate into an incident. Not all problems can be spotted and remediated before they start affecting upstream applications. You must decide how your application will react when it cannot send messages during outages.
Availability is a service quality that needs to be considered in depth. By doing all the operational basics right, you significantly decrease the likelihood of outages at the platform level. If you are using Confluent Cloud, then we take care of the best practices around running the platform on your behalf.
This blog post covered several options for outage handling. The exact strategy that is right for you depends on your applications’ transaction model, the value of inbound data, and its throughput. These factors must be considered against the cost of implementing additional reliability mechanisms that go beyond those provided natively by Kafka and its client libraries.
If you would like to discuss reliability with people who deal with it daily, please contact Professional Services to learn more.
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Kafka-docker-composer: A Simple Tool to Create a docker-compose.yml File for Failover Testing
The Kafka-Docker-composer is a simple tool to create a docker-compose.yml file for failover testing, to understand cluster settings like Kraft, and for the development of applications and connectors.


How to Process GitHub Data with Kafka Streams
Learn how to track events in a large codebase, GitHub in this example, using Apache Kafka and Kafka Streams.