Fast, Frictionless, and Secure: Explore our 120+ Connectors Portfolio | Join Webinar!
Infinite Storage in Confluent Platform
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
A preview of Confluent Tiered Storage is now available in Confluent Platform 5.4, enabling operators to add an additional storage tier for data in Confluent Platform. If you’re curious about how and why we built this feature and the kinds of use cases it unlocks, please read on!
Motivation behind Tiered Storage
As part of managing Confluent Cloud, Apache Kafka® re-engineered for the cloud, we often find inefficiencies and bottlenecks as our Kafka footprint grows. We developed Tiered Storage to make Confluent Platform and Confluent Cloud more scalable, cost efficient, and easier to run operationally.
Improved scalability and elasticity
To make Confluent Platform more scalable and elastic, it needs to be able to scale and balance workloads very quickly. Adding or removing brokers requires shifting partitions between brokers, which can be a time-consuming operation. Moving data between brokers also creates contention for resources with production traffic, which may cause performance degradation for users.
Any partition that is moved must be fully replicated to the destination broker for the rebalance to complete. The additional replication traffic consumes more network and CPU resources from an already resource-constrained cluster. Although replication traffic can be throttled, this will only further increase the time it takes to move the partition and achieve balance.
Tiered Storage makes storing huge volumes of data in Kafka manageable by reducing this operational burden. The fundamental idea is to separate the concerns of data storage from the concerns of data processing. With this separation, it becomes much easier to scale each independently.
When using Tiered Storage, the majority of the data is offloaded to the remote store. When rebalancing, only a small subset of the data on the broker’s local disk must be replicated between replicas. This results in large operational improvements by reducing the time and cost to rebalance, expand or shrink clusters, or replace a failed broker.
Additional storage tiers also make it possible to use different storage types at the broker level to improve performance and cost profile. With Tiered Storage, you could use SSDs for low-latency reads and writes near the tail of the log as well as for cheaper, scalable object stores like Amazon S3, Google Cloud Storage, etc., when it comes to high-throughput historical reads. In its preview phase as a feature of Confluent Platform, Tiered Storage only supports Amazon S3.
Enabling Kafka as a system of record
There is much to love about Kafka when used as the system of record for all of your data. By retaining data in Kafka, it can be easily reprocessed or backloaded into new systems. Today, as the amount of data stored in Kafka increases, users eventually hit a “retention cliff,” at which point it becomes significantly more expensive to store, manage, and retrieve data. To work around this, operators and application developers typically use an external store like Amazon S3 as a sink for long-term storage. This means you lose most of the benefits of Kafka’s immutable log and offsets, and instead end up having to manage two different systems with different access patterns.
What if data could be stored in Kafka forever, though? You could then get all the benefits of the immutable log and use Kafka as the single source of truth for all events. Just imagine the various use cases for storing data in Kafka forever. We talked about some of these in an earlier blog post, but here’s a few more:
- Storing a stream of events in Kafka and computing materialized views on top of that to visualize year-over-year changes, etc., using a stream processing job
- Machine learning applications being able to train new models using historical streams of data
- A new change-data-capture-style application being built that requires a full dump of the data to be loaded in
- More easily meeting regulatory requirements by storing events in Kafka longer
And how do you reduce the associated costs of storing and managing all of this data? Tiered Storage allows you to offload the majority of the data to a remote store. This allows for a cheaper form of storage that readily scales with the volume of data. Additionally, operators no longer have to worry about managing or rebalancing this data as part of their Kafka cluster. Because of this, we believe that Tiered Storage will unlock many new use cases stemming from infinite retention.
Easier infrastructure planning
It’s possible to mismanage clusters and exhaust broker disk space when using time-based retention to limit the amount of data on a per-broker basis. Estimating the amount of data that will be produced within a given time can be difficult as it is highly subject to demand.
However, cloud-native object stores effectively scale infinitely. Tiered Storage means you no longer have to choose between retention times and exhausting your disk or needing to unexpectedly expand disks or clusters. Tiered Storage greatly reduces the need for these interventions, which are time consuming and often difficult to reverse.
Goals for implementing Tiered Storage
We set out with several goals for implementing Tiered Storage within the heart of Kafka’s storage sub-system.
Durability and integrity
The most important goal for us was to ensure correctness. It is critical that the storage layer for Confluent Platform runs reliably and predictably and returns correct results, especially since the storage layer touches many of the most critical operations in Kafka. If data stored in Kafka is not durable or cannot be correctly consumed, then little else matters.
Seamless for operators
An important advantage of Tiered Storage is ease of operational use. It frees the operator from most of the pains of capacity planning and having to think about storage itself.
To make Tiered Storage easy to set up and manage, all that is needed is this minimum set of configurations:
confluent.tier.feature=true confluent.tier.enable=true confluent.tier.backend=S3 confluent.tier.s3.bucket=<BUCKET_NAME> confluent.tier.s3.region=<REGION>
Once these configurations are specified, the broker seamlessly archives data to the specified remote store and retrieves it when needed.
Seamless for developers
It was crucial to make Tiered Storage completely transparent to application developers so that they do not need to rewrite their applications. This means all Kafka features are supported seamlessly and transparently within the broker, including but not limited to transactional processing, exactly once processing, the ability to fetch data from the closest replica, etc.
Portability
In order for our implementation to be agnostic of the backing store, allowing a variety of remote storage solutions to be “plugged into” it, the implementation must not make too many assumptions about the capabilities and consistency semantics of the underlying store. This means we are able to support eventually consistent object stores like Amazon S3, as well as file or block storage devices like the Hadoop Distributed File System (HDFS), without requiring changes to the core of our implementation. For the preview release, we support Amazon S3 out of the box. We are also working on support for other object stores like Google Cloud Storage and Azure Blob storage for future releases.
Performance
The additional work to tier data to a remote store must happen in the background with little interference to the user workload. While Tiered Storage competes with the user workload for CPU and network resources, we put the appropriate mechanisms in place to to throttle or burst tiering operations as required so that they do not interfere with normal user workload. This is similar to how Kafka implements quotas for replication data. In steady state, we can also keep up with data being produced into Kafka so that the size of the local disk remains bounded.
Furthermore, when data is replayed from the head of the log (or from a relatively old portion of the log), these reads must be able to catch up to the tail of the log. This means delivering sustained, high-throughput reads, regardless of whether the reads are being served from Tiered Storage.
Implementation of Tiered Storage
So how does Tiered Storage really work under the hood? At a high level, the idea is very simple: move bytes from one tier of storage to another. There are three main tasks to perform: tier eligible data to remote storage, retrieve tiered data when requested, and garbage collect data that is past retention or has been deleted otherwise. All of this happens seamlessly in the broker and requires no changes to application logic.
What is the challenge in building this feature if it’s as easy as moving bytes around? Like all distributed systems, things fail, move, and change underneath us. And this is the primary challenge: ensuring the process works accurately, reliably, predictably, and consistently across all brokers—in spite of partition movements, broker failures, etc.—with minimal disruption to user workload.
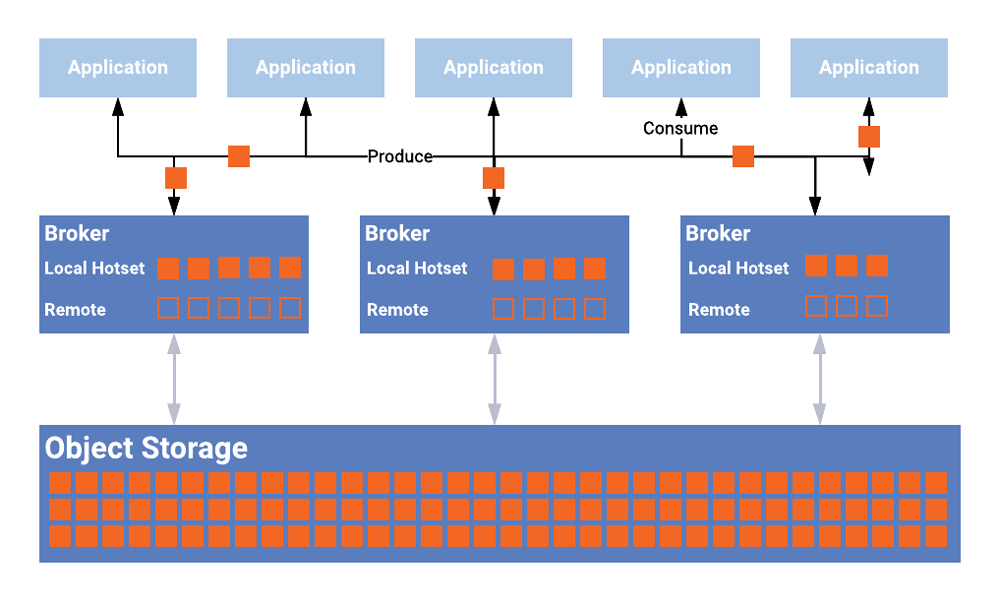
Tiering data
A Kafka partition is composed of multiple segment files, which is also the unit of data movement for Tiered Storage. Data produced to a partition is first written into a page cache and periodically flushed to a local disk. If the partition has replicas, they perform the same action of copying the data into a page cache and flushing it to a local disk periodically.
Once the segment rolls and is flushed to the disk, the data becomes eligible for being archived to remote storage and can subsequently be deleted from local storage based on the configured hotset. The leader of the partition is responsible for tiering data to remote storage. An internal Kafka topic called _confluent-tier-state tracks the metadata for segments residing in remote storage.
The hotset discussed above is a notion that we introduced with Tiered Storage as a way of specifying the amount of data to be held on the broker’s local disk even if it has already been copied over to remote storage. The hotset should typically be configured to equal the size of the page cache on the broker. The hotset allows real-time reads near the tail of the consumer to be read directly from the page cache. Data residing outside the hotset is read from the configured remote store.
The hotset retention is configurable at the broker or topic level using confluent.tier.local.hotset.ms and confluent.tier.local.hotset.bytes. The diagram below shows a Kafka partition, with the tiered and untiered portions of the log, including the local hotset.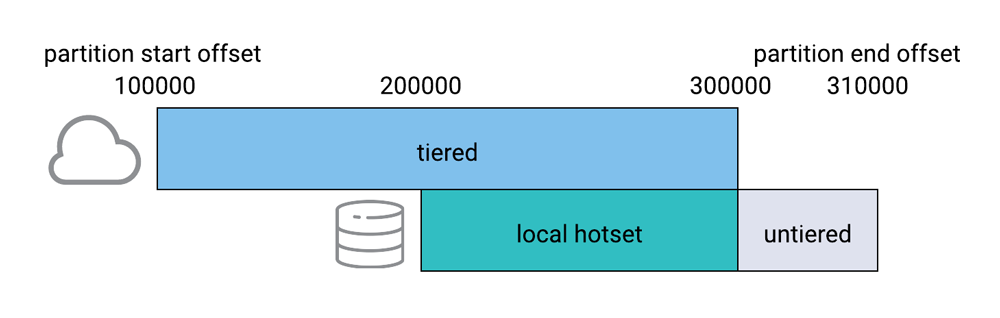
Fetching data
The internal metadata topic is used as the source of truth for the data that exists in remote storage. Brokers create a view of the log like the one above based on this metadata and the current state of the log on local storage. When a request to consume a certain offset is received, the broker determines whether the fetch can be satisfied locally from the hotset or the untiered portion of the log. If it can, this data is returned right from the page cache using existing Kafka mechanisms. If the data of interest is no longer present on local storage, then the corresponding data is brought into the broker by reading it from remote storage before serving it back to clients.
An important consideration is where this read from remote storage happens so that we do not end up blocking other requests, especially requests that are trying to produce to or consume from the tail of the log. With our implementation, reading data from Tiered Storage will have more desirable caching and I/O characteristics, as the I/O path for real-time produce and consume traffic is now completely independent of lagging consume traffic.
Garbage collection of data
Data may become unused and unreferenced over time as topics are deleted and recreated or when segments are past the configured retention. The Kafka broker runs a set of garbage collection threads to be able to delete such data from remote storage. Whenever data is deleted from remote storage, corresponding events are also written to the internal metadata topic. This process for garbage collection runs asynchronously and does not block any user operations, such as being able to recreate topics.
Final thoughts
At Confluent, we are committed to our mission to build a complete event streaming platform and help companies rearchitect themselves around this paradigm shift. As we continue to make Confluent Platform more reliable and scalable, Tiered Storage takes us further along this journey by making the platform elastic, more cost effective, easier to manage operationally, and viable for new workloads.
Confluent also remains committed to improving Apache Kafka. By way of KIP-405, which proposes to add Tiered Storage support to Kafka, we are actively working with the community on the design proposal and related interfaces that could be used and adopted by the open source community. You can read about it in the discussion thread.
We have a lot of exciting work in our pipeline. If you are passionate about building distributed systems and solving hard problems, Confluent is hiring! Join us in shaping the future of the event streaming world.
Ready to get started?
If you’d like to know more, you can download the Confluent Platform to get started with Tiered Storage and a complete event streaming platform built by the original creators of Apache Kafka.
You can also learn more about Tiered Storage in the documentation and try the demo.
Along with us, an amazing team of distributed systems engineers and product managers worked for over a year to bring our vision for Tiered Storage to fruition: Addison Huddy, Colin Hicks, Gardner Vickers, Ismael Juma, Jun Rao, Matthew Wong, Michael Drogalis, Nikhil Bhatia, Tim Ellis, and the entire Kafka Team at Confluent.
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Schema Registry Clients in Action
Learn about the bits and bytes of what happens behind the scenes in the Apache Kafka producer and consumer clients when communicating with the Schema Registry and serializing and deserializing messages.

How to Securely Connect Confluent Cloud with Services on Amazon Web Services (AWS), Azure, and Google Cloud Platform (GCP)
The rise of fully managed cloud services fundamentally changed the technology landscape and introduced benefits like increased flexibility, accelerated deployment, and reduced downtime. Confluent offers a portfolio of fully managed...