Introducing Connector Private Networking: Join The Upcoming Webinar!
How Krake Makes Floating Workloads on Confluent Platform
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Organizations today are moving their data and their data processing workloads to the cloud, and often into multiple clouds. Hybrid cloud solutions, cloud-native application architectures, and event streaming systems—especially in the context of machine learning (ML) and artificial intelligence (AI) systems—are hot topics these days. Besides compute power and processing speed, energy efficiency is becoming more and more important. Even Google datacenters work harder when the sun is shining.
This blog post is based on the Confluent Platform and open source multi-cluster workload scheduler called Krake from Cloud&Heat. It explores the use of floating workloads for improving data processing efficiency and streaming data management. This blog post also focuses on flexible workload migration between datacenters and introduces key concepts.
Enable flexible workload placement and real data transparency
Traditionally, cloud computing has been composed of one to multiple large to very large datacenters. This approach has several limitations, such as:
- Legal limitations: Sensitive data needs to be processed within a certain regulation zone, which might be different from where the central cloud platform is sitting in.
- Technical limitations: Real-time applications with strict low-latency requirements cannot run in a central cloud platform.
- Energy limitations: Though huge progress has been made over the past few years with water-cooling technology, the energy efficiency optimization of single datacenters is reaching its limits.
It is possible, however, to overcome these limitations, leading us to believe that the future of cloud computing is decentralized—composed of a multitude of geographically distributed and heterogeneous datacenters in terms of hardware (e.g., presence of GPUs), software (e.g., cloud platform technology), capacity, and performance.
With this decentralized approach, cloud applications are run on a plethora of datacenters that fit their regional legal, technical, and energy requirements. To efficiently orchestrate them, optimizing the energy utilization of the distributed cloud infrastructure globally can be achieved by shifting applications between sites or delaying the execution of applications, depending on ecological factors.
Event streaming will emerge as the central nervous system of digital business in the future. As Confluent co-founder and CEO Jay Kreps writes, “It isn’t just that businesses use more software, but that, increasingly, a business is defined in software. That is, the core processes a business executes—from how it produces a product, to how it interacts with customers, to how it delivers services—are increasingly specified, monitored, and executed in software.” Software requires data in real time and flexible processing capabilities.
A combined approach: Confluent Platform and Cloud&Heat
Confluent Platform is an event streaming platform based on Apache Kafka®, the open source streaming software for scalable event stream processing. With Confluent Platform, you get an enterprise-ready ecosystem. This allows you to manage and process streams of events, and also persist large amounts of events in a scalable way. With ksqlDB and Kafka Streams (KStreams) applications (both are included in the Confluent Platform), you can process streams of data while the data is in motion, at scale and in real time.
Instead of managing file transfers and traditional extract, transform, load (ETL) processes, Cloud&Heat uses the Confluent Platform to create data planes transparently over multiple micro datacenters and cloud providers. Transparent access to event streaming data is a critical success criteria for the adoption of event-driven architectures.
Using Confluent Platform’s Global capabilities, we can create a highly available, durable, and globally distributed event streaming fabric that will serve as the data plane for our applications orchestrated by Krake. We can stretch Confluent Platform using Multi-Region Clusters to achieve low RTOs and RPOs, combined with Cluster Linking, which allows us to link our different clusters together all over the world.
With these global capabilities, we can design systems that make it easier to ensure data sovereignty, all the while, creating systems that ensure high availability and durability.
Now that we have a highly available, globally distributed data plane powered by Confluent Platform, let’s look at the application layer. Krake is an open source orchestration engine for containerized and virtualized workloads across distributed and heterogeneous cloud platforms initiated by Cloud&Heat. It creates a thin layer of aggregation on top of various platforms (such as OpenStack, Kubernetes, or Red Hat OpenShift) and presents them through a single interface to the cloud user. The user’s workloads are scheduled depending on both user requirements (hardware, latencies, and cost) and the platforms’ characteristics (energy efficiency, heat demand, and load). The scheduling algorithm can be optimized for latencies, cost, and energy, to name a few. Krake can be leveraged for a wide range of application scenarios, such as central management of distributed compute capacities, as well as application management in edge cloud infrastructures.
In summary:
- Confluent addresses the “data plane”—data can be ingested and consumed at any point of the distributed infrastructure without user intervention
- Krake addresses the “application plane”—applications can be deployed at any point of the distributed infrastructure without user intervention.
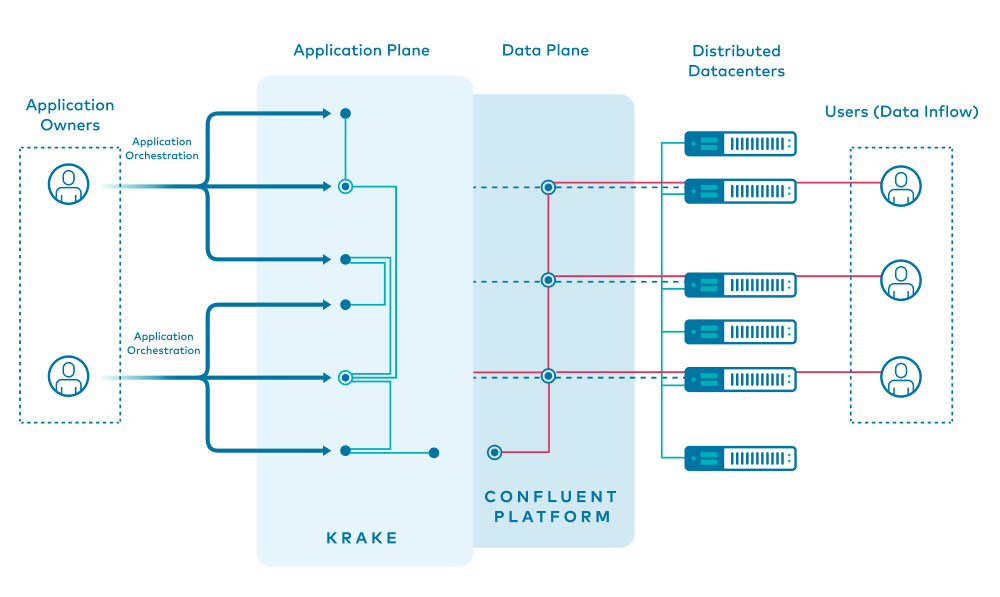 Custom dataflows across distributed datacenters will be enabled by the combination of a data plane and application plane. This gives application owners the freedom to choose compute locations according to ecological and economical considerations, while the data is provisioned and distributed automatically in real time.
Custom dataflows across distributed datacenters will be enabled by the combination of a data plane and application plane. This gives application owners the freedom to choose compute locations according to ecological and economical considerations, while the data is provisioned and distributed automatically in real time.
This new approach leads to synergy and accomplishes the following objectives:
- Distributed datacenters: Enable the full advantages of edge cloud platforms for cloud users, including applications which previously didn’t fit the cloud model
- Global datacenter linking: Confluent Platform allows you to create a data plane between and across datacenters, which will exist as central systems or as decentralized solutions. Such a data plane provides the integration and transportation mechanisms for global cluster integration and Cluster Linking. The result is transparent access to data streams and data assets managed by the data plane.
- Software-defined energy efficiency: Optimize the energy efficiency of the distributed cloud Infrastructure through load shifting and delayed execution.
What are cloud-native applications?
According to Wikipedia, “Cloud-native applications are built as a set of microservices that run in Docker containers, orchestrated in Kubernetes.” Why is this special? Wikipedia says, “The advantage of using Docker containers is the ability to package all software needed to execute into one executable package. The container runs in a virtualized environment, which isolates the contained application from its environment.” In general, an application does not necessarily have to be a microservice. But there is something missing in this definition: Where is the data in a cloud-native system? The data should be in the cloud as well, so that a cloud-native application can work with it.
Historically, and also driven by demand, individual workload types shift to the cloud at very different speeds. For example, there are the stateless services that process a particular request—this means they work predominantly on the data contained in the request, and not much more external data is needed. This particular workload type is a common example and applies for many use cases, especially related to real-time data enrichment and classification systems.
The cloud-native approach allows for easy scale out of the service by providing more instances as soon as the demand increases. The same is possible the other way around. During off hours with less demand, we simply turn off containers so that you save money. In cloud-native systems, this is really easy. The flexibility exists in the domain of time. At different times, we use a various number of deployments to adjust to your needs. We call this workload “customer-bound.”
Resource-bound workloads
In addition to time-based scaling to fulfill customer demand, we can use time-based scaling to utilize available resources better during periods when cost is low. This pattern does not adapt well to the “customer-bound” workload type because it depends on available resources. Hence, this workload type is called “resource bound.” There are many workloads in the field of enterprise IT where regular processing can be scheduled and executed in batch mode. People are often heard saying, “Nobody wants batch processing these days.” But, wait, is this right? Should we really ignore data lakes and big data projects? Obviously not!
In many of our field projects, we observe that even if many applications are rearchitected for real-time stream processing, we continue to find many applications where intensive workloads are executed from time to time and regularly in batches. The training of machine learning models is a prominent batch processing use case, and scientific simulation, 3D, and video rendering, etc., are more examples of batch processing. Managing such workloads is, again, an event-driven procedure.
The appropriate placement of an execution window can make a huge difference in such cases. Being able to flexibly run a workload with high-processing latency in the range of a month or a day later at half of the cost is a huge potential economic optimization. The trend toward stream processing should not ignore this. In this section, we introduced a second workload type: “resource-bound,” which enables the processing of heavy volumes without exact time requirements and at the lowest possible cost.
Distributed streaming workload
A distributed streaming model assumes that cloud computing costs vary within a cloud system—otherwise, there is not much benefit of running a workload at a particular point in time. This workload type has no additional advantage compared to the resource-bound workload as long as the cloud provider’s cost model is static. But in the case of very flexible pricing models, which are aligned on compute demand, available energy (energy cost), and resource trading, we will see a huge impact.
A third type of application is a distributed streaming application, managed in several regions where each region offers an individual pricing model due to variable energy costs and variable utilization of the heat given off during computation. In this environment, we can save money and work more efficiently due to flexible workload placement across regions. Flexible workload placement enables cost savings as processing runs where the energy is cheap and provides an unprecedented means to control data delivery latency (not to be confused with processing latency as mentioned above). This enables you to leverage the advantages of future cloud-native applications. Multi-cloud or multi-region workload placement adds more flexibility to the operational model of a particular cloud-native application.
According to the Cloud Native Computing Foundation (CNCF), “Cloud-native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservices, immutable infrastructure, and declarative APIs exemplify this approach.”
All definitions of the concept cloud native have one problem in common: Data-intensive applications don’t fit well into this approach. The requirements do not cover the flexibility of workload placement, nor do they cover transparent data provisioning.
This is especially true for data-heavy, real-time event streaming applications, as defined by our third workload type, so we have to add the following requirements:
- Allow flexible workload placement across clouds and cloud regions
- Provide a transparent data plane with a high degree of data locality and reliable, asynchronous background replication
Today’s enterprise IT infrastructures are typically very complex, and multiple perspectives coexist. So far, only the workload perspective has been discussed. Before we can continue with a precise problem statement and our solution, we must introduce another facet, which is driving the development of next-generation datacenters.
The following section presents our approach to closing a gap that currently exists in the cloud world.
Which problem do we address?
There are actually two problems that we care about:
- Flexible workload placement
- Transparent availability of data streams via data planes
Confluent and Cloud&Heat address both of these problems by focusing on cloud-native IT and open source software. In the following section, we provide a reference architecture for cloud-native event streaming applications in a hybrid cloud, real-world context, based on a customer scenario.
Why should you care about flexible workload placement and data transparency?
With rising demand for multi-datacenter and multi-cloud integration, it’s become more and more obvious that future cloud systems will be decentralized by nature. In the future of compute:
- Applications that require low latency run close to the user or close to the data they consume.
- Applications run in a specific geographical area to meet specific legal regulations.
- The cost of running an application in the cloud is reduced by placing the application in a location where the computation is offered at ideal conditions (cost, energy, and data availability).
- Compute-intensive applications with a low-availability requirement are executed when conditions (e.g., cost or energy efficiency) are optimal, instead of ad hoc in a random fashion and being paused the rest of the time.
- Infrastructure providers improve the overall energy efficiency of their infrastructure by placing workloads where the carbon footprint is the lowest.
- Energy providers dynamically notify when and where the energy should be consumed. They use the workload migration as a replacement to energy shifting.
Whereas running an application on top of such an infrastructure provides many advantages, it comes at a complex cost to its lifecycle management. Given the decentralized structure of future cloud systems (multi cloud, hybrid cloud, decentralized private clouds, etc.), vendors have to provide solutions for managing dataflows between datacenters and for workload migration.
The open source software Krake eases up the lifecycle management of compute-intensive workloads. It optimizes the application placement based on a set of configurable metrics, performs automatic migration whenever a “better” fit is found, and allows automatic scale down of workload once its computation is finished.
Confluent Platform provides all the technical means for establishing and unifying data pipelines between various places and implements a variety of technologies from all relevant vendors.
Core concepts of our solution
Our solution is based on three technologies:
- Kubernetes provides the resource management and provisioning services for our runtime
- Confluent Platform handles the data processing and data integration requirements for our streaming data workloads
- Krake is responsible for identifying the ideal place to request a particular workload.
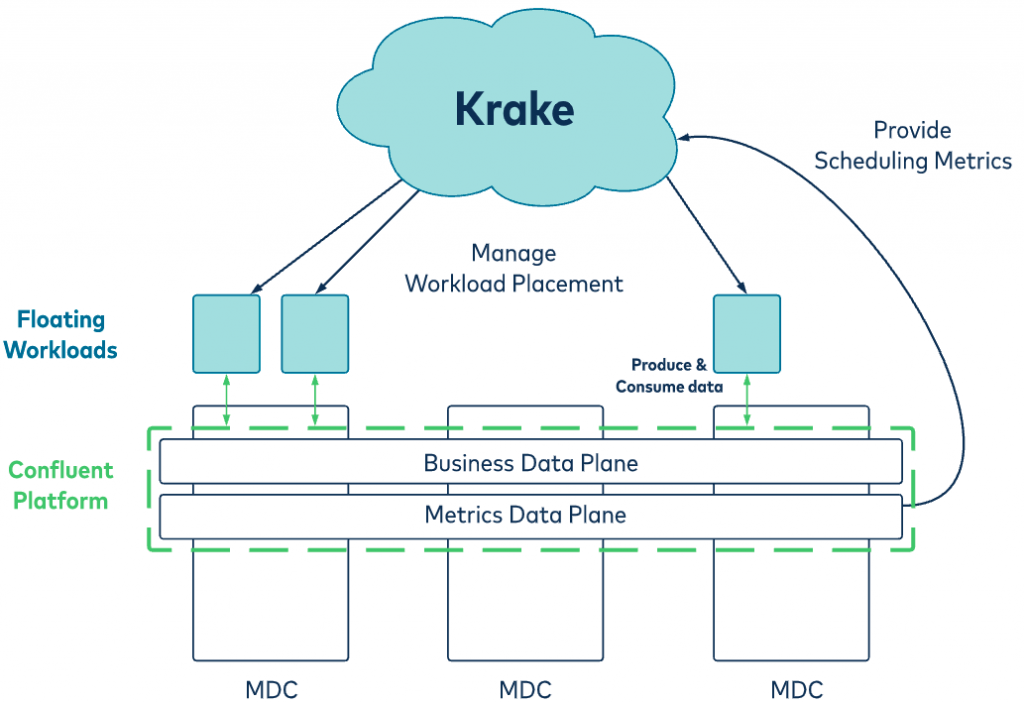
Figure 2. The metrics data plane collects performance and monitoring data about the running applications and datacenters. Krake leverages those scheduling metrics to orchestrate the placement of floating workloads. The business data plane contains the data consumed by the floating workloads. That data is replicated across all datacenters by the Confluent Platform. Hence, the migration of the floating workload by Krake to a new site becomes possible.
Figure 2 shows our cross-datacenter scheduler Krake, which moves flexible workloads to an ideal location in multiple micro datacenters (MDC). The data plane
provides input data for the Krake scheduler and also captures the output data of data-centric workloads, such as event streaming applications or stream processing applications, in a transparent way. This layer is provided by the Kafka-based Confluent Platform.
What is a micro datacenter?
A micro datacenter is a unit of managed compute and storage resources, either in the cloud or even provided as on-premises hardware, with integration to both local data infrastructure and local facilities like heating solutions and energy buffers. The micro datacenter includes a container management system, such as Kubernetes or Minikube. This means that a micro datacenter can be simulated by a PC running Minikube or within any cloud environment that offers a Kubernetes-compatible service.
What do we mean when we speak about workloads?
Traditionally, a workload was defined as the activity that takes place when you start a program on a computer. Many systems had a single machine or a set of machines that all served a well-defined purpose in layered architectures. For a compute workload, you have a well-defined input that has to be processed in order to generate the system’s output as shown in Figure 3. The workload is defined by the amount of data that a computer has to handle. In the past, the assumption was simply that your data is already on the machine that processes it.
Architectural innovation and new technology has emerged over time, and remote storage allows you to process data loaded from remote locations in a transparent way. As long as you have a bounded processing context, this can be handled easily. But especially in the case of event stream processing we are able to handle an unbounded processing context.
This makes the setup a bit different. We need a new definition for the workload or, even better, for the processing context. First, we must aim for flexibility in execution time and execution location. Then, we have to take the characteristics of the continuous data flows into account.
Stateless programs, which are executed in containers and expose an API, are containerized stateless workloads. They can be used via REST or RPC clients, and they can run anywhere at any time in our modern cloud-based datacenters (including the Cloud&Heat micro datacenters). For programs that work on continuous streams at the same time, you can also use the containerized approach. This concept needs to be extended via integration with a data plane, which brings us to the notion of a floating workload.
What is a floating workload?
A floating workload (FWL) is a program packaged in containers (including runtime configuration, security related settings, and domain-specific, static-side data), which can easily be started in any cloud by a global workload scheduler. The data that is processed by a floating workload is provided by a data plane. A transparent data plane decouples the unit of compute work from the external systems that house the data. This reduces the complexity of distributed solutions.
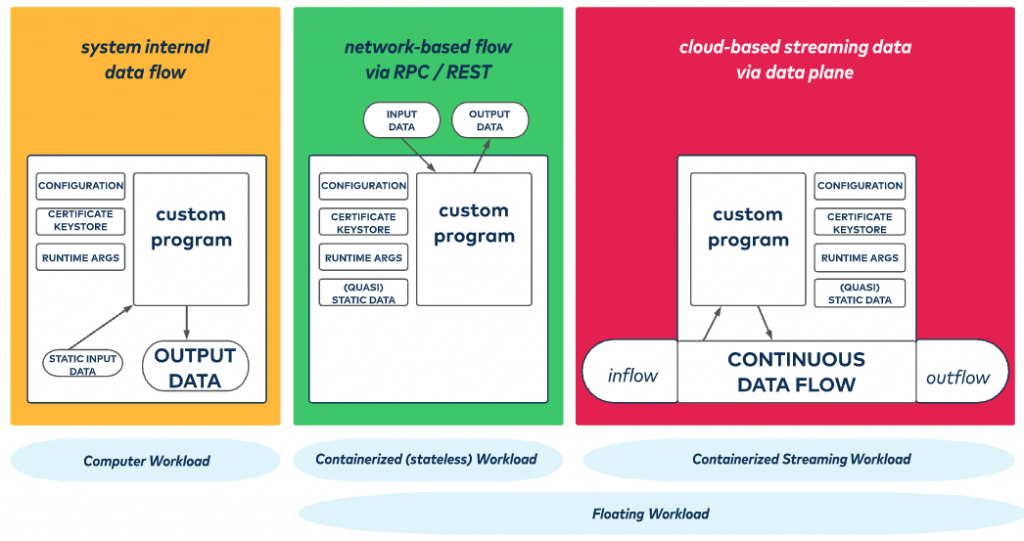 Figure 3. There are three typical workload types: compute workload, which is alway executed in the place where it is deployed; floating workloads, which can be moved to different locations, assuming that the data is available wherever the workload is scheduled—floating workloads can be either stateless or stateful streaming programs.
Figure 3. There are three typical workload types: compute workload, which is alway executed in the place where it is deployed; floating workloads, which can be moved to different locations, assuming that the data is available wherever the workload is scheduled—floating workloads can be either stateless or stateful streaming programs.
Any kind of data processor that consumes data from Kafka can become a floating workload. Specifically, ksqlDB servers and KStreams applications are used in our demo scenario, which will be described in more detail in our next two articles. Each application instance can be configured with its own optimal resource footprint. Thus, monitoring and metrics collection are needed. We use the data plane for two flavors of data: process data and metadata about the process. Finally, all this supports transparent data provisioning and flexible workload migration.
What is a data plane and how does the data move around?
A data plane is a system that provides event streams across multiple clouds, no matter what infrastructure is underneath it. This can be any cloud, from public clouds to private clouds and hybrid clouds, including micro datacenters.
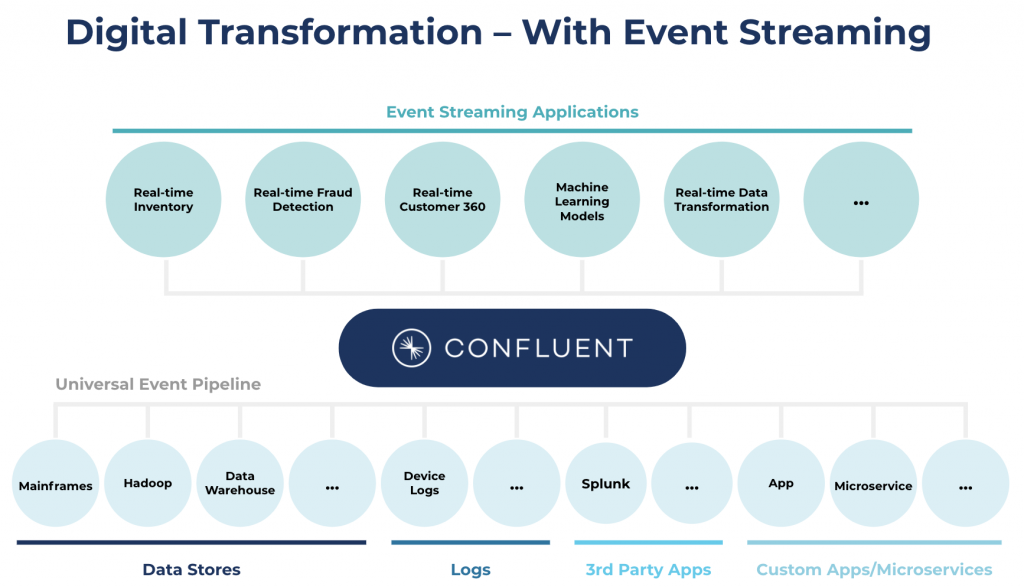 Figure 4: Integration of event and data streams across a variety of enterprise IT systems leads to simplified architectures.
Figure 4: Integration of event and data streams across a variety of enterprise IT systems leads to simplified architectures.
The illustration above shows the integration of dataflows from and to a variety of services via Confluent Platform. Because modern IT infrastructure spans multiple locations and several organizations, spanning the data plane on a global scale is required as well.
A data plane provides data to container-based distributed applications. These need to consume data in a transparent way from multiple locations so that the location of processing is not limited to only one datacenter.
The data plane has to handle multiple types of data for different scenarios. This allows individual optimizations for transport and persistence based on available resources using specific configurations of the data plane. Some data assets can be persisted on a data plane, while others just flow via the data plane between specialized subsystems. Our Kafka-based data plane is not the replacement of special purpose datastores, such as data warehouses or graph and time series databases, but it simplifies the dataflows between multiple applications and also between organizations.
Our demo scenario illustrates the usage of a floating workload over a data plane that is primarily used for global data distribution and for global access to the data. The throughput and latency requirements are moderate. Durability and continuity of the processing flows are key factors for the success of this solution. Both are supported by asynchronous multi-region replication provided by Confluent Platform, which is introduced in the next section.
Our first demo uses a Docker Compose based setup to provide a fast solution, but a Confluent Operator based deployment on Kubernetes is our real target for this kind of system.
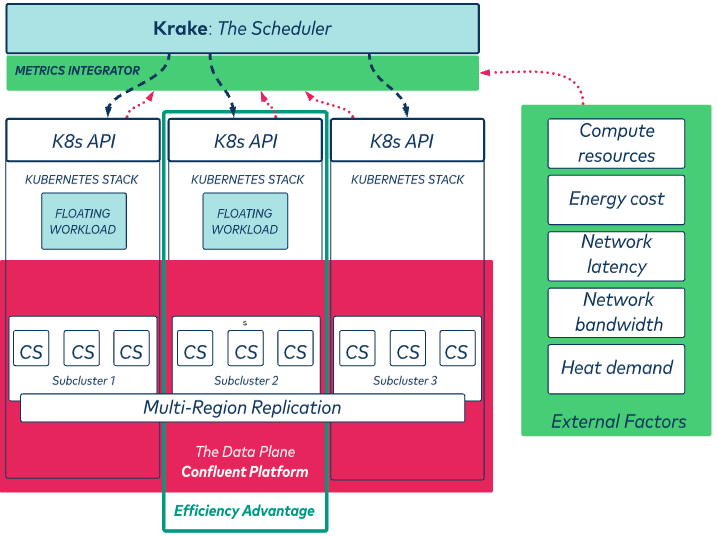 Figure 5. Components of our solution are shown. Additional factors such as energy prices, heat demand, and available network bandwidth can be injected via the metric data plane to influence how Krake allocates resources.
Figure 5. Components of our solution are shown. Additional factors such as energy prices, heat demand, and available network bandwidth can be injected via the metric data plane to influence how Krake allocates resources.
Figure 5 brings all the components and concepts discussed in this article together. It illustrates how a floating workload can be moved between two subclusters or between two regions using Krake, which on its own, takes operational data of the data plane and additional context data into account for efficient scheduling decisions.
Summary and outlook
This first blog post explains why we use a two-layer data plane to manage floating workloads for improving processing efficiency. The first layer of the data plane integrates data streams from various sources to support workload placement optimization. The second layer provides the data to the floating workloads in a transparent way.
Confluent Platform (no matter where it is deployed—on prem or as managed service in the cloud) help you establish a transparent, scalable data plane over datacenters for managing any kind of event streaming data. The data plane is also used to manage the processing context for flexible job placement with the multi-cluster workload scheduler Krake.
Interested in more?
If you’d like to know more, you can download the Confluent Platform to get started with a complete event streaming platform built by the original creators of Apache Kafka.
We’d like to thank our friends and colleagues who supported our work by providing resources, giving their time during technical sessions, and reviewing the report. We thank you all so much for your support: Dr. Marius Feldmann, Mark Schulze, Victoria Yu, Samantha Seaman, Jakub Korab, Juan Fraire, Antony Stubbs, Konstantin Silin, and Sven Knop.
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Tech-Enabled Metropolises: The Role of Data Streaming in Smart Cities
According to the World Bank, around 56% of the world’s population currently live in cities. By 2050, it’s predicted this will rise to 70% (with the global population more than doubling in the same time frame). This acceleration toward urbanization is putting city infrastructure under enormous strain



Unlocking Industry 4.0: Rise of Smart Factory with Data Streaming
In the era of Industry 4.0, the fusion of smart, autonomous systems with digitization is propelling manufacturing and supply chain operations into uncharted efficiency. Industry 4.0, otherwise known as the Fourth Industrial Revolution, marks the normalization of the smart factory.