Introducing Connector Private Networking: Join The Upcoming Webinar!
Getting Your Feet Wet with Stream Processing – Part 2: Testing Your Streaming Application
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Part 1 of this blog series introduced a self-paced tutorial for developers who are just getting started with stream processing. The hands-on tutorial introduced the basics of the Kafka Streams API and ksqlDB, as well as common patterns for designing and building event-driven applications.
Developers who modernize their architectures with Apache Kafka® get two obvious benefits from this streaming platform:
1. Rich set of APIs to develop applications that process streaming data in real time
2. Confluent Cloud, which provides Kafka as a service to offload the burden of infrastructure management
 But there is another important vector for developers to consider: validation. Validating that a solution works is just as important as implementing one. It provides assurances that the application is working as designed, can handle unexpected events and can evolve without breaking existing functionality, etc. Since validating an application is just as important as implementing it in the first place, building an event-driven architecture with Kafka has an additional benefit:
But there is another important vector for developers to consider: validation. Validating that a solution works is just as important as implementing one. It provides assurances that the application is working as designed, can handle unexpected events and can evolve without breaking existing functionality, etc. Since validating an application is just as important as implementing it in the first place, building an event-driven architecture with Kafka has an additional benefit:
3. Ecosystem of tools for validating Kafka streaming applications
Let’s explore the ways our community validates applications at different phases of development:
- Unit testing
- Integration testing
- Avro and schema compatibility testing
- Confluent Cloud tools
- Multi-datacenter testing
Unit testing
When you create a stream processing application with Kafka’s Streams API, you create a Topology either using the StreamsBuilder DSL or the low-level Processor API. Normally, the topology runs with the KafkaStreams class, which connects to a Kafka cluster and begins processing when you call start(). For testing though, connecting to a running Kafka cluster and making sure to clean up state between tests adds a lot of complexity and time.
Instead, developers can unit test their Kafka Streams applications with utilities provided by kafka-streams-test-utils. Introduced in KIP-247, this artifact was specifically created to help developers test their code, and it can be added into your continuous integration and continuous delivery (CI/CD) pipeline.
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-streams-test-utils</artifactId> <version>2.1.0</version> <scope>test</scope> </dependency>
To test business logic across sub-topologies, use the TopologyTestDriver. It is a drop-in replacement for the KafkaStreams class and has no external dependencies on a running Kafka cluster. It processes input synchronously so you can use the built-in hooks to verify the results immediately after providing input.
If you are using lambdas for ValueJoiner or KeyValueMapper functions, you can write unit tests using the TopologyTestDriver. You can also query state stores maintained by your application under test.
// Example Using DSL
StreamsBuilder builder = new StreamsBuilder();
builder.stream("input-topic").filter(...).to("output-topic");
Topology topology = builder.build();
// Example Using Processor API Topology topology = new Topology(); topology.addSource("sourceProcessor", "input-topic"); topology.addProcessor("processor", ..., "sourceProcessor"); topology.addSink("sinkProcessor", "output-topic", "processor");
// Setup TopologyTestDriver Properties config = new Properties(); config.put(StreamsConfig.APPLICATION_ID_CONFIG, "test"); config.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "dummy:1234"); TopologyTestDriver testDriver = new TopologyTestDriver(topology, config);
If the application uses the Processor API, you can test the internals with lightweight and fast unit tests. KIP-267 introduces a general purpose MockProcessorContext, which allows inspection of data from a custom processor. Developers pass in MockProcessorContext during initialization of an instantiated object from the Processor API, and then they verify behavior.
Developers pass in MockProcessorContext during initialization of an instantiated object from the Processor API, and then they verify behavior.
final Properties config = new Properties();
final MockProcessorContext context = new MockProcessorContext("test-app", new TaskId(0, 0), config);
final KeyValueStore<String, Long> myStore = ...;
context.register(myStore, false, null);
final Processor<String, Long> processor = new MyProcessor();
processor.init(context);
// Verify some processor behavior processor.process("a", 1L); processor.process("a", 2L); final KeyValue<Object, Object> capture1 = context.forwarded().get(0); Assert.assertEquals(new KeyValue<>("a", 1L), capture1);
If you have a client application using Kafka producers or consumers, you may leverage the utilities for MockProducer and MockConsumer. These utilities enable you to unit test client application in parts. For example, if you have a producer in a REST API server, you can test the REST code by replacing the KafkaProducer with a MockProducer.
Or, if you have developed any custom components—perhaps you have written your own custom partitioner or serializer—you can use MockProducer to test just the custom components. By simulating the producer or consumer, you can test more specific code paths. To use these, import the kafka-clients artifact as a dependency.
For reference examples of TopologyTestDriver, MockProcessorContext, MockProducer and MockConsumer, check out the Apache Kafka GitHub repo. You may also read the Confluent documentation on testing streaming applications. For the newest usage of TopologyTestDriver with TestInputTopic and TestOutputTopic, read this blog post.
Integration testing
After unit testing, developers need to test the application’s asynchronous interaction with a Kafka cluster. This integration testing validates that the individual components work seamlessly together and satisfy higher-level application logic.
Before doing testing against a real Kafka cluster, you may want to test against a simulated Kafka cluster. For this purpose, you can use EmbeddedKafkaCluster, which is also part of kafka-streams-test-utils. It allows for parallelism, is applicable for multi-threaded or multi-instance Kafka Streams applications and has fault injection capabilities, like stopping applications.
For reference examples of EmbeddedKafkaCluster, check out the integration tests in the Apache Kafka GitHub repo. Note that EmbeddedKafkaCluster is subject to change between releases.
Avro and schema compatibility testing
There is an implicit “contract” that Kafka producers write data with a schema that can be read by Kafka consumers, even as producers and consumers evolve their schemas. These producers and consumers may be those that you develop directly in your client applications, as well as the producers and consumers embedded with Kafka Streams and ksqlDB.
Kafka applications depend on these schemas and expect that any changes made to schemas are still compatible and able to run. This is where Confluent Schema Registry helps: It provides centralized schema management and compatibility checks as schemas evolve.
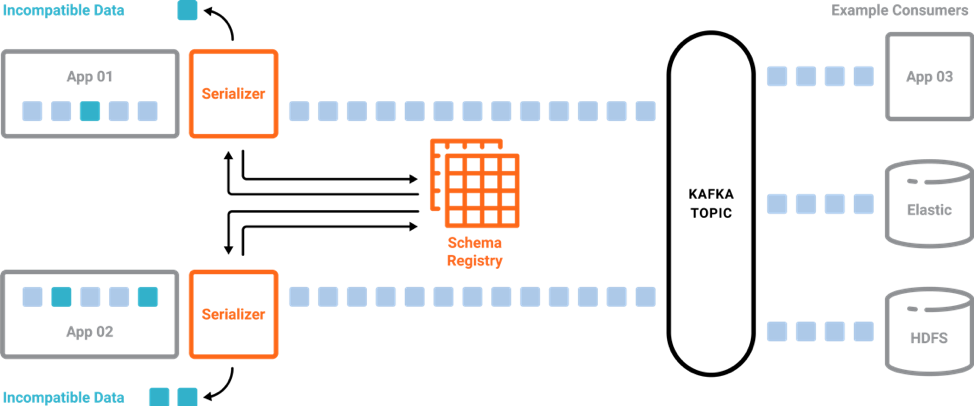
If you are using Schema Registry and Avro serialization in your applications, you can simulate a Schema Registry instance in your unit testing. Use Confluent Schema Registry’s MockSchemaRegistryClient to register and retrieve schemas that enable you to serialize and deserialize Avro data. For reference examples of MockSchemaRegistryClient, check out the ksqlDB GitHub repo.
As we started building examples of streaming applications and tests using the Kafka Streams API along with Confluent Schema Registry, we started using the EmbeddedSingleNodeKafkaCluster. Although it is not part of Apache Kafka, it is very similar to the EmbeddedKafkaCluster discussed earlier but also provides a Confluent Schema Registry instance. For reference examples of EmbeddedSingleNodeKafkaCluster, visit the Kafka Streams Examples GitHub repo.
After your applications are running in production, schemas may evolve but still need to be compatible for all applications that rely on both old and new versions of a schema. Confluent Schema Registry allows for schema evolution and provides compatibility checks to ensure that the contract between producers and consumers is not broken. This allows producers and consumers to update independently as well as evolve their schemas independently, with assurances that they can read new and legacy data.
Confluent provides a Schema Registry Maven plugin, which you can use to check the compatibility of a new schema against previously registered schemas. For further details, read the documentation on schema evolution and compatibility.
<plugin> <groupId>io.confluent</groupId> <artifactId>kafka-schema-registry-maven-plugin</artifactId> <version>5.0.0</version> <configuration> <schemaRegistryUrls> <param>http://localhost:8081</param> </schemaRegistryUrls> <subjects> <transactions-value>src/main/resources/avro/io/confluent/examples/clients/basicavro/Payment2a.avsc</transactions-value> </subjects> </configuration> <goals> <goal>test-compatibility</goal> </goals> </plugin>
Confluent Cloud tools
Up till now, this blog post has focused on testing your applications with simulated environments. Next, we look at testing your applications in a more realistic deployment scenario for additional test coverage that takes into account network connectivity, latency, throughput, etc., and its effects on your applications.
If you are using Confluent Cloud, you should test your applications with your cloud instances. You may also want to test with other services from Confluent Platform, such as Confluent Schema Registry, Confluent REST Proxy, Kafka Connect, ksqlDB and Confluent Control Center. There are two ways to run those services: in the cloud or locally.
![]()
If you want to run those services in the cloud, check out the tools for Confluent Cloud. These Terraform scripts provision Confluent Platform services to automatically connect to your Confluent Cloud cluster. They handle creating the underlying infrastructure details, like VPC, subnets, firewalls, storage, compute and load balancers, as well as bootstrapping any processes that are necessary to install and configure the services. Once those services are running in the cloud, you may validate your application works over the real network. Disclaimer: these tools are just for testing—they are not supported for production.
To run the services locally instead, you can use this Docker setup. On the host from which you are running Docker, ensure that you have properly initialized Confluent Cloud CLI and have a valid configuration file at $HOME/.ccloud/config. Use the script provided in the project to auto-generate a file of environment variables used by Docker to set the bootstrap servers and security configuration. See the README for more details. Disclaimer: This Docker setup is just for testing—it is not supported for production.
Multi-datacenter testing
If you run applications across multiple clouds, public or private, you need a data backbone that can span all of the clouds. What is more, you may want to move Kafka data between deployments. Here are a few scenarios when you may want to transfer Kafka data from other clusters to Confluent Cloud:
- For disaster planning, enterprises copy data to different sites to prevent complete loss of data. Read more in Disaster Recovery for Multi-Datacenter Apache Kafka Deployments.
- For streaming applications connecting to Confluent Cloud, any Kafka data in other clusters that the application needs should also be copied to the Confluent Cloud instance.
- Bridge to cloud to migrate existing data from self-managed to fully managed Kafka with Confluent Cloud. Read more in the bridge-to-cloud deployment guide.
These papers provide building blocks that you can use to build your multi-datacenter solution. For testing, adapt the configurations to be more representative of your production deployment and test your streaming applications against them. If you are planning for disaster recovery, simulate an event that results in one datacenter failure, validate Kafka failover and failback, test your runbook and verify consumers can resume reading data where they left off.
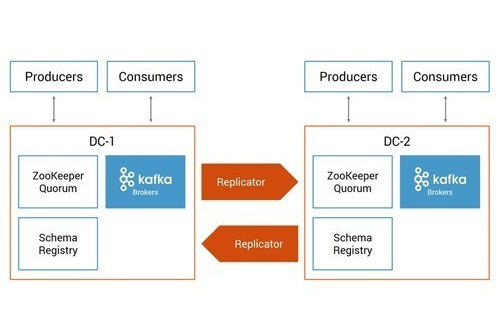
To help you with the testing, Confluent provides a Docker setup in a GitHub repository. Clone this repository and then bring up an active-active multi-datacenter environment leveraging the new Replicator features, such as provenance headers to prevent cyclic replication of topics, timestamp preservation and consumer offset translation. Disclaimer: This is just for testing—do not take this Docker setup into production.
Learn more about Apache Kafka
Our end goal is to help your business be successful with Kafka. Regardless of how you integrate Kafka into your core workflow, we hope this blog post helps guide you through testing streaming applications at all levels—from unit testing up to multi-datacenter.
To learn more about Apache Kafka as a service, check out Confluent Cloud, a fully managed event streaming service based on Apache Kafka. Use the promo code CL60BLOG to get an additional $60 of free Confluent Cloud usage.*
Related articles
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Introducing Versioned State Store in Kafka Streams
Versioned key-value state stores, introduced to Kafka Streams in 3.5, enhance stateful processing capabilities by allowing users to store multiple record versions per key, rather than only the single latest version per key as is the case for existing key-value stores today...


Delivery Guarantees and the Ethics of Teleportation
This blog post discusses the two generals problems, how it impacts message delivery guarantees, and how those guarantees would affect a futuristic technology such as teleportation.